
Anthropic just released Claude Sonnet 4.5, and the company is billing it as nothing less than the best coding model in the world. Continue reading “Anthropic Launches Claude Sonnet 4.5”
Anthropic just released Claude Sonnet 4.5, and the company is billing it as nothing less than the best coding model in the world. Continue reading “Anthropic Launches Claude Sonnet 4.5”
Agentic AI is the next frontier in artificial intelligence. It’s the evolution of AI into autonomous decision‑makers that can plan, act and adapt without continuous human oversight. For technology leaders and entrepreneurs, understanding agentic AI isn’t optional; it’s critical to staying competitive. In this guide, we’ll explore what agentic AI is, how it works, why it matters today, and how to integrate it responsibly—sprinkled with expert insights, research data, and Clarifai‑powered recommendations.
Keep reading for an in‑depth journey into the future of agentic AI—and discover how Clarifai’s tools can help you harness it.
Question: What is agentic AI and why should businesses care in 2025? Answer: Agentic AI refers to artificial intelligence systems designed with autonomy and agency that can independently plan, decide and act toward goals, distinguishing them from traditional rule‑based or generative models. Its importance lies in enabling businesses to move from reactive automation to proactive decision‑making—freeing teams to focus on high‑value work while agents handle complex workflows.
Agentic AI stands at the intersection of autonomy, adaptability and reasoning. Unlike generative models that produce text or images, agentic systems can set sub‑goals, decide the best path forward and execute actions across multiple steps. They combine large language models (LLMs) with external tool integrations—from APIs to robotics—allowing them to navigate dynamic environments and evolve over time.
Why now? The adoption of generative AI has been rapid, yet many companies report little bottom‑line impact. According to a 2025 research survey, nearly 80 % of companies use generative AI, but only a handful have seen significant returns. This “gen‑AI paradox” underscores a need to move beyond chatbots toward goal‑oriented agents that can transform entire processes and unlock new revenue streams. McKinsey points out that agents can automate complex workflows, shifting AI from a reactive assistant to a proactive collaborator. Additionally, industry analysts predict the global autonomous agents market will surge from $4.35 billion in 2025 to $103.28 billion by 2034, reflecting explosive demand.
Question: How is agentic AI different from traditional and generative AI? Answer: Traditional AI follows predefined rules to perform specific tasks, generative AI creates new content based on training data, and agentic AI not only generates content but also autonomously plans and executes actions toward goals.
To understand the leap from conventional automation to agency, consider the following comparison:
|
Feature |
Traditional AI |
Generative AI |
Agentic AI |
|
Primary function |
Automating repetitive tasks |
Generating text, code or images |
Goal‑oriented decision‑making and action |
|
Autonomy |
Low—follows predefined rules |
Variable—requires user prompts |
High—acts with minimal supervision |
|
Learning style |
Based on static algorithms |
Data‑driven (deep learning) |
Reinforced learning with feedback and environmental adaptation |
|
Scope |
Limited, narrow domains |
Content creation |
Cross‑domain reasoning and multi‑step execution |

Question: How have AI agents evolved, and what categories of agentic systems are available? Answer: AI agents have progressed from simple rule‑based chatbots to sophisticated entities that incorporate natural language understanding, reasoning, memory and multi‑agent collaboration. The main categories include reactive agents, proactive agents and specialized agents tailored for tasks like information retrieval, knowledge curation and workflow execution.
Question: What are the core steps an agentic AI follows to achieve a goal? Answer: An agentic AI system follows a loop of Perceive, Reason, Act and Learn—gathering data, planning and decision‑making, executing tasks via tools or APIs, and improving through feedback.
Agents first collect information from diverse sources: user prompts, sensors, databases or external APIs. They use perception modules to extract meaningful patterns and identify entities. For example, a customer service agent gathers ticket details, user history and real‑time sentiment.
A reasoning engine, often an LLM integrated with retrieval‑augmented generation (RAG), interprets the goal and plans the steps to achieve it. It sequences tasks, picks the right tools and weighs trade‑offs. Reinforcement learning can improve decision‑making over time.
Once a plan is ready, the agent executes actions by interacting with software, sending API calls, running code or controlling physical devices. Built‑in guardrails ensure compliance with rules and safety guidelines. For instance, a finance agent may approve refunds only up to a certain amount and flag higher values for human review.
Agents maintain a feedback loop. They collect results of their actions, evaluate outcomes and refine their models to improve performance. This continuous learning forms a data flywheel—the more interactions, the smarter the agent becomes.
In complex scenarios, a managing agent orchestrates multiple specialized sub‑agents. For example, one agent may handle data retrieval, another performs reasoning, and a third executes actions. This architecture mirrors human teams, distributing tasks among agents based on expertise.

Question: What types of agentic AI agents exist and how are they applied? Answer: There are reactive agents, proactive agents and specialized agents (information retrieval, prescriptive knowledge, workflow action and user assistant). Each category serves different purposes—from responding to immediate stimuli to orchestrating complex workflows.
Reactive agents operate based on current stimuli. In cybersecurity, a reactive agent detects anomalous behavior and instantly isolates a compromised endpoint. They are essential for real‑time threat detection and automated incident response.
Proactive agents anticipate needs and set goals. A marketing agent might monitor campaign performance, shift budgets and optimize channels without waiting for instructions. In finance, an agent could reallocate funds to prevent overdraft fees.
These agents extract and synthesize knowledge from large datasets using generative models. They are ideal for research, customer support and knowledge management. Because they handle less‑regulated content, they operate with more flexibility.
In regulated industries, prescriptive agents provide compliant answers. For instance, a healthcare agent must adhere to medical guidelines and ensure patient safety when recommending treatments.
Action agents plan and execute workflows across multiple applications, often using API calls. They automate tasks like onboarding new employees, managing supply chains or processing customer orders. By orchestrating sequences of actions, they reduce manual handoffs and boost efficiency.
User assistant agents serve as digital colleagues—scheduling meetings, responding to messages and managing personal tasks. They are the foundation for digital office assistants and consumer AI products.
The market is seeing a rise in vertical agents for specific industries. Examples include healthcare diagnostic agents, code‑generation agents for software developers and supply chain agents for logistics. These agents deliver higher accuracy by leveraging domain‑specific knowledge.
Question: What advantages does agentic AI offer to businesses and individuals? Answer: Agentic AI provides autonomous execution, proactive decision‑making, multi‑step reasoning, improved customer experiences, operational efficiency, revenue growth and cost reduction.
Agentic AI systems can complete workflows without constant supervision, reducing manual workload and freeing employees to focus on high‑value tasks. A retail agent can process orders, update CRM records, initiate deliveries and notify customers—all autonomously.
Agents analyze real‑time data and anticipate needs, adjusting strategies before problems arise. In marketing, an agent might shift ad spend from underperforming channels; in inventory management, it can reorder stock before shortages occur.
Many business workflows involve multiple steps and dependencies. Agentic AI excels at breaking goals into sub‑tasks, adjusting actions based on results and coordinating across systems. This leads to more accurate and efficient processes.
By delivering personalized, immediate responses, agents improve satisfaction and loyalty. A customer support agent can resolve inquiries, track orders, issue refunds and follow up without human escalation.
Agents operate 24/7, scaling operations without additional staff. They reduce labor costs and minimize errors. The global autonomous agents market is predicted to grow dramatically because organizations see significant ROI: increased revenue, faster time‑to‑market and streamlined operations.
Early adopters of agentic AI gain a strategic edge. Proprietary agent frameworks, refined data and optimized processes become difficult for competitors to replicate. PwC estimates that agentic AI could contribute $2.6–4.4 trillion annually to global GDP by 2030.

Question: What are some real‑world applications and examples of agentic AI across industries? Answer: Agentic AI is transforming IT support, HR, finance, cybersecurity, healthcare, manufacturing, retail, and more. It manages tasks like self‑healing data pipelines, adaptive HR support, fraud detection, threat hunting and autonomous vehicles.
Agentic AI autonomously identifies and resolves IT issues—resetting passwords, deploying software and diagnosing complex problems—before they disrupt operations. Clarifai’s Compute Orchestration can integrate these workflows by managing infrastructure and model inference pipelines.
In HR, agents automate resume screening, interview scheduling and benefits inquiries, providing personalized responses. They can integrate with Clarifai’s local runners to process sensitive data securely on‑premise and maintain compliance.
Financial agents manage expense reporting, fraud detection, compliance checks and financial forecasting, analyzing large data volumes in real time. They even automate personal finance tasks like transferring funds to avoid overdrafts.
Agents in cybersecurity perform real‑time threat detection, adaptive threat hunting, offensive security testing and case management. They monitor network traffic, detect anomalies and respond autonomously—reducing incident response times.
Healthcare agents assist with diagnostics, medical coding, appointment scheduling and resource allocation. For example, a 2025 AI nursing system provides patient monitoring and advice at a lower cost.
Agents manage warehouse robotics, inventory forecasting and logistics planning. They integrate with physical devices to optimize production lines and reduce downtime. Advanced agents even negotiate shipping routes and adjust schedules on the fly.
Autonomous agents handle order processing, returns, personalized recommendations and customer inquiries—delivering faster service and reducing manual workload. They can also monitor sentiment and adapt interactions to improve customer experiences.
In smart homes, agents control heating, lighting and appliances, optimizing energy use and comfort. They learn residents’ preferences and adjust settings automatically.
Imagine a boutique e‑commerce company. An agent monitors sales trends, automatically increases ad spend on high‑performing products, reorders inventory before it runs out, replies to customer questions and processes returns. The owner focuses on product design and marketing strategy, while the agent keeps operations running.
Question: What does the current adoption landscape look like for agentic AI? Answer: Adoption is accelerating. About 14 % of organizations currently deploy AI agents at partial or full scale, while 93 % of leaders believe those who scale agents in the next year will gain an advantage. Market forecasts anticipate 75 % of enterprises using AI agents by 2026.
Question: What are the main challenges and ethical considerations when implementing agentic AI? Answer: Key challenges include accountability, data quality, integration complexity, human resistance, privacy risks, over‑reliance on automation, and evolving regulatory requirements.
Determining who is responsible when an agent makes a wrong decision is complex. Liability could fall on developers, deploying organizations or the AI itself. Clear governance frameworks and audit trails are essential.
Agents require high‑quality, unified data. Many organizations struggle with incomplete, inconsistent or siloed datasets, making integration expensive and error‑prone. Legacy systems often lack APIs needed for seamless agent integration.
Employees may fear job displacement or distrust autonomous systems. Successful adoption demands transparent communication, reskilling programs and psychological safety.
Autonomous agents can create new attack vectors. AI‑powered data leaks and adversarial attacks pose serious risks. Compliance with privacy regulations (GDPR, CCPA) becomes more complex as agents process personal data across jurisdictions.
Relying too heavily on agents may erode human oversight and critical judgment. High‑stakes domains like healthcare and finance still require human supervision to handle ambiguous or ethical decisions.
Dependence on particular AI vendors can limit flexibility and create lock‑in. The rapid pace of innovation means today’s platform might be obsolete in a few years.
Ensuring fairness, transparency and accountability requires robust ethical frameworks, explainability techniques and human‑in‑the‑loop oversight. Without them, autonomous systems risk perpetuating biases or making opaque decisions.

Question: What frameworks and technologies support the development of agentic AI? Answer: Popular frameworks include OpenAI Swarm, LangGraph, Microsoft Autogen, CrewAI and other multi‑agent toolkits. Agent orchestration platforms and open‑source models also play a critical role.
Agentic systems often run on orchestration platforms that coordinate interactions between agents, data sources and tools. These platforms manage concurrency, memory storage, error handling and policy enforcement. They also support multi‑agent ecosystems, enabling specialized agents to work together.
Organizations increasingly adopt open‑source LLMs (e.g., Mistral, Anthropic) to reduce costs and maintain privacy. Fine‑tuning these models on proprietary data enhances performance while retaining control.
Agentic AI must connect to a variety of tools—APIs, databases, code execution environments and IoT devices. Clarifai’s model inference and compute orchestration help by providing scalable infrastructure and easy deployment of multimodal models. Local runners allow sensitive data processing on local hardware, maintaining privacy while leveraging powerful AI.
Frameworks should allow human intervention when agents reach decision boundaries. Configurable thresholds ensure that high‑risk actions get escalated.
Question: How can businesses successfully adopt agentic AI? Answer: Key strategies include assessing readiness, defining clear goals, selecting the right agents, ensuring data quality, integrating with existing systems, piloting responsibly, establishing governance and investing in talent.
Identify workflows that would benefit most from autonomy—such as repetitive support tasks, data processing or decision‑heavy operations. Evaluate whether these processes have reliable data and clearly defined outcomes.
Set specific, measurable goals for agentic deployments. Use KPIs such as decision speed, error reduction, cost savings and customer satisfaction.
Choose agents that fit your domain: reactive agents for real‑time responses, proactive agents for strategic planning, or workflow agents for complex sequences. For regulated industries, ensure agents comply with industry guidelines.
Invest in data quality improvement, including data augmentation and master data management. Establish single sources of truth and implement real‑time synchronization.
Develop API‑first, cloud‑native infrastructure with microservices and containerization. Clarifai’s compute orchestration can manage large‑scale model inference and deployment across cloud or on‑prem environments.
Start with low‑risk pilots. Use stage‑gate investment processes—scale only when pilots demonstrate value. Continuously monitor performance and refine agents.
Create AI Centers of Excellence and federated governance structures that balance central oversight with business unit autonomy. Define policies for agent decision‑making, escalation and auditing.
Develop training programs to build AI literacy, including prompt engineering and data analysis skills. Implement mentorship programs pairing AI‑savvy employees with those learning to work with agents. Foster a culture where humans collaborate with agents.
Question: What trends will shape agentic AI in the next few years? Answer: Emerging trends include self‑healing data pipelines, vertical specialization, integration with IoT and physical environments, open‑source model momentum, synthetic data, AI agent frameworks boom, multimodal AI and evolving pricing models.
Future pipelines will monitor, diagnose and repair themselves, using agentic systems to ensure data integrity and availability.
Agentic AI shifts focus from designing processes to deploying tools that automate workflows end‑to‑end. This reduces the need for complex process design.
Specialized agents for industries like healthcare, finance, coding and logistics deliver higher precision and efficiency. Expect to see agent marketplaces where businesses can adopt off‑the‑shelf vertical solutions.
Agents will increasingly interact with the physical world via smart homes, factories and cities, controlling devices and robots autonomously.
The rise of open models reduces barriers to entry and fosters innovation, allowing organizations to fine‑tune models in‑house.
Transformative AI involves systems that deconstruct complex goals under uncertainty, leverage external tools and adapt strategies over time. TAI systems will drive high‑impact change at scale.
New frameworks (LangGraph, CrewAI, Autogen) simplify building multi‑agent systems. Expect ecosystem growth and standardization.
Combining synthetic and real data will overcome scarcity and bias, enabling agents to train on diverse scenarios.
Agents are reshaping team roles—analysts handle more technical tasks while engineers automate workflows. Pricing models are shifting toward pay‑per‑task or hourly rates for digital co‑workers.
Multimodal models will process text, images, audio and video, enabling richer reasoning. Ethical considerations and energy consumption will become central to adoption decisions.
Question: What lessons can we learn from real‑world deployments of agentic AI? Answer: Case studies demonstrate significant productivity gains, cost savings and operational improvements but also highlight the need for data readiness, governance and human oversight.
A data observability company developed self‑healing pipelines that monitor data flows, diagnose issues and autonomously repair errors, reducing downtime and improving data quality. This case shows the potential for agentic AI to maintain infrastructure autonomously.
In healthcare, a startup introduced AI nursing agents priced around $10 per hour, significantly lower than the median hourly wage for human nurses. These agents handle routine patient monitoring, freeing nurses to focus on complex care. However, the deployment required stringent ethical oversight and clear escalation procedures.
A global bank uses an AI agent to review legal contracts, completing 360,000 hours of human work in seconds. This enabled legal teams to shift from administrative work to strategic analysis. The key challenge was ensuring model accuracy and incorporating human review for critical clauses.
Logistics companies deploy agents to forecast demand, reorder inventory and negotiate shipping routes, improving efficiency and reducing costs. Agents operate 24/7, adjusting to disruptions in real time.
Medical AI systems like diagnostic agents assist clinicians by interpreting medical images and recommending actions. These agents improve diagnostic speed and accuracy but must comply with strict regulatory standards.
In software development, code‑generation agents suggest improvements, debug code and generate small applications. They work as junior developers, increasing productivity and reducing errors.

Question: What are the social and workforce implications of agentic AI? Answer: Agentic AI reshapes job roles, necessitates reskilling, raises ethical concerns about displacement and requires thoughtful integration to ensure fairness and trust.
Agents should be seen as digital coworkers rather than replacements. Teams need to develop communication protocols and trust mechanisms to work effectively alongside agents.
Question: What steps should organizations and individuals take to prepare for widespread agentic AI adoption? Answer: Preparation involves building AI literacy, investing in data governance and infrastructure, establishing governance models, developing AI talent pipelines and adopting ethical and regulatory frameworks.
Educate employees about agentic AI, including how to interact with agents, interpret their outputs and provide feedback. Encourage cross‑functional learning and knowledge sharing.
Implement data quality programs, master data management and real‑time synchronization. Ensure data is accessible, secure and compliant with regulations.
Set up AI Centers of Excellence to centralize expertise, create standards and oversee projects. Adopt federated governance to balance central control with local autonomy.
Pilot agentic solutions in low‑risk areas, evaluate results and scale gradually. Use AI‑specific financial metrics—such as decision speed improvement or customer satisfaction—to measure impact.
Ensure compliance with emerging AI regulations. Incorporate ethical considerations—fairness, transparency, privacy—into design. Use interpretability techniques and maintain audit trails for decisions.
Clarifai provides compute orchestration to manage large‑scale model inference, model inference APIs for deploying multimodal models, and local runners for on‑premise deployments. These tools enable organizations to build and run agentic AI responsibly and efficiently.
Agentic AI represents a transformational leap beyond generative or traditional AI. By combining autonomy, reasoning and action, agents promise to boost productivity, unlock new value and reshape industries. However, success hinges on responsible implementation—ensuring data quality, ethical governance, transparency, and human collaboration. As adoption accelerates and markets grow, early movers who invest in trusted agentic systems will gain significant advantages.
Clarifai is uniquely positioned to support your agentic AI journey through compute orchestration, model inference and local runners that simplify deployment while maintaining security and compliance. Start small with low‑risk pilots, build robust data foundations, and create a culture of human‑AI partnership—and you’ll be ready to thrive in the era of autonomous agents.
Agentic AI refers to AI systems with agency—they can autonomously plan, decide and act toward goals, going beyond mere content generation.
Generative AI produces content (text, code, images) in response to prompts, whereas agentic AI combines generation with planning and autonomous execution.
Applications include self‑healing data pipelines, autonomous IT support, HR agents for recruiting, finance agents for fraud detection, cybersecurity agents for threat hunting, healthcare diagnostic agents and autonomous vehicles.
Challenges include data quality, integration complexity, trust and transparency issues, regulatory compliance, and change management.
Clarifai offers compute orchestration for managing AI models, model inference APIs for deploying multimodal AI, and local runners that process data securely on‑prem. These tools provide the infrastructure needed to develop and scale agentic systems.
Agentic AI will reshape jobs—automating repetitive tasks and enabling employees to focus on higher‑level strategic work. Organizations need to invest in reskilling and create new roles that complement AI.
Emerging trends include self‑healing data pipelines, vertical agents, integration with IoT, synthetic data, open‑source models, multimodal AI and new pricing models for digital co‑workers. Continued innovation will drive adoption and sophistication.
OpenAI just flipped the switch on a feature that transforms ChatGPT into a full-blown shopping platform. Continue reading “ChatGPT Just Got “Instant Checkout””
Artificial intelligence has moved from being a buzzword to a critical driver of business innovation, personal productivity, and societal transformation. Companies across sectors are eager to leverage AI for automation, real‑time decision-making, personalized services, advanced cybersecurity, content generation, and predictive analytics. Yet many teams still struggle to move from concept to a functioning AI model. Building an AI model involves more than coding; it requires a systematic process that spans problem definition, data acquisition, algorithm selection, training and evaluation, deployment, and ongoing maintenance. This guide will show you, step by step, how to build an AI model with depth, originality, and an eye toward emerging trends and ethical responsibility.
Quick Summary—How do you build an AI model?
Building an AI model involves defining a clear problem, collecting and preparing data, choosing appropriate algorithms and frameworks, training and tuning the model, evaluating its performance, deploying it responsibly, and continuously monitoring and improving it. Along the way, teams should prioritize data quality, ethical considerations, and resource efficiency while leveraging platforms like Clarifai for compute orchestration and model inference.
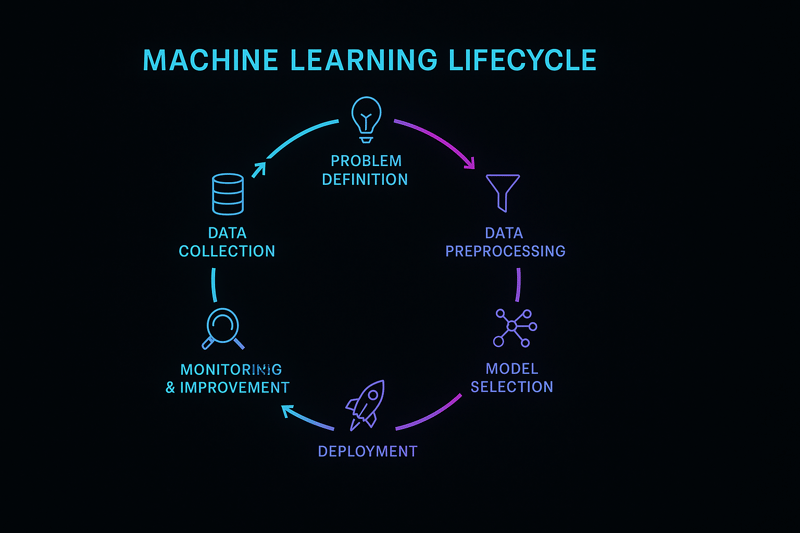
The first step in building an AI model is to clarify the problem you want to solve. This involves understanding the business context, user needs, and specific objectives. For instance, are you trying to predict customer churn, classify images, or generate marketing copy? Without a well‑defined problem, even the most advanced algorithms will struggle to deliver value.
Start by gathering input from stakeholders, including business leaders, domain experts, and end users. Formulate a clear question and set SMART goals—specific, measurable, attainable, relevant, and time‑bound. Also determine the type of AI task (classification, regression, clustering, reinforcement, or generation) and identify any regulatory requirements (such as healthcare privacy rules or financial compliance laws).
Imagine a manufacturing company that wants to reduce downtime by predicting when machines will fail. The problem is not “apply AI,” but “forecast potential breakdowns in the next 24 hours based on sensor data, historical logs, and environmental conditions.” The team defines a classification task: predict “fail” or “not fail.” SMART goals might include reducing unplanned downtime by 30 % within six months and achieving 90 % predictive accuracy. Clarifai’s platform can help coordinate the data pipeline and deploy the model in a local runner on the factory floor, ensuring low latency and data privacy.
Data is the fuel of AI. No matter how advanced your algorithm is, poor data quality will lead to poor predictions. Your dataset should be relevant, representative, clean, and well‑labeled. The data collection phase includes sourcing data, handling privacy concerns, and preprocessing.
Suppose you’re building an AI system to classify flowers. You could collect images from public datasets, upload your own photos, and ask community contributors to share pictures from different regions. Then, label each image according to its species. Remove duplicates and ensure images are balanced across classes. Finally, augment the data by rotating and flipping images to improve robustness. For privacy‑sensitive tasks, consider generating synthetic examples using generative adversarial networks (GANs).
After defining your problem and assembling a dataset, the next step is selecting an appropriate algorithm. The choice depends on data type, task, interpretability requirements, compute resources, and deployment environment.
Suppose you need to classify customer feedback into categories (positive, negative, neutral). For a small dataset, a Naive Bayes or support vector machine might suffice. If you have large amounts of textual data, consider a transformer‑based classifier like BERT. For domain‑specific accuracy, a fine‑tuned model on your data yields better results. Clarifai’s model zoo and training pipeline can simplify this process by providing pretrained models and transfer learning options.
Tools and frameworks enable you to build, train, and deploy AI models efficiently. Choosing the right tech stack depends on your programming language preference, deployment target, and team expertise.
Let’s say you want to create a customer‑support chatbot. You can use Clarifai’s pretrained language models to recognize user intent and generate responses. Use Flask to build an API endpoint and containerize the app with Docker. Clarifai’s platform can handle compute orchestration, scaling the model across multiple servers. If you need on‑device performance, you can run the model on a local runner in the Clarifai environment, ensuring low latency and data privacy.
 Training and Tuning Your Model
Training and Tuning Your ModelTraining involves feeding data into your model, calculating predictions, computing a loss, and adjusting parameters via backpropagation. Key decisions include choosing loss functions (cross‑entropy for classification, mean squared error for regression), optimizers (SGD, Adam, RMSProp), and hyperparameters (learning rate, batch size, epochs).
Suppose you train an image classifier. You might experiment with learning rates from 0.001 to 0.1, batch sizes from 32 to 256, and dropout rates between 0.3 and 0.5. Clarifai’s platform can orchestrate multiple training runs in parallel, automatically tracking hyperparameters and metrics. Once the best parameters are identified, Clarifai allows you to snapshot the model and deploy it seamlessly.
Evaluation ensures that the model performs well not just on the training data but also on unseen data. Choose metrics based on your problem type:
Divide the data into training, validation, and test sets to prevent over‑fitting. Use cross‑validation when data is limited. For time series or sequential data, employ walk‑forward validation to mimic real‑world deployment.
Suppose you built a model to predict customer churn for a streaming service. Evaluate precision (the percentage of predicted churners who actually churn) and recall (the percentage of all churners correctly identified). If the model achieves 90 % precision but 60 % recall, you may need to adjust the threshold to catch more churners. Visualize results in a confusion matrix, and check performance across age groups to ensure fairness.
Deployment turns your trained model into a usable service. Consider the environment (cloud vs on‑premises vs edge), latency requirements, scalability, and security.
A fintech company trains a model to identify fraudulent transactions. They containerize the model with Docker, deploy it to AWS Elastic Kubernetes Service, and expose it via FastAPI. Clarifai’s platform helps orchestrate compute resources and provides fallback inference on a local runner when network connectivity is unstable. Real‑time predictions appear within 50 milliseconds, ensuring high throughput. The team monitors the model’s precision and recall to adjust thresholds and triggers an alert if performance drops below 90 % precision.
AI models are not “set and forget” systems; they require continuous monitoring to detect performance degradation, concept drift, or bias. MLOps combines DevOps principles with machine learning workflows to manage models from development to production.
A company deploys a voice assistant that processes millions of voice queries daily. They monitor latency, error rates, and confidence scores in real time. When the assistant starts misinterpreting certain accents (concept drift), they collect new data, retrain the model, and redeploy it. Clarifai’s monitoring tools trigger an alert when accuracy drops below 85 %, and the MLOps pipeline automatically kicks off a retraining job.
AI systems can create unintended harm if not designed responsibly. Ethical considerations include privacy, fairness, transparency, and accountability. Data regulations (GDPR, HIPAA, CCPA) demand compliance; failure can result in hefty penalties.
Consider an AI model that predicts heart disease from wearable sensor data. To protect patients, data is encrypted on devices and processed locally using a Clarifai local runner. Federated learning aggregates model updates from multiple hospitals without transmitting raw data. Model cards document the training data (e.g., 40 % female, ages 20–80) and known limitations (e.g., less accurate for patients with rare conditions), while the system alerts clinicians rather than making final decisions.
In healthcare, AI accelerates drug discovery, diagnosis, and treatment planning. IBM Watsonx.ai and DeepMind’s AlphaFold 3 help clinicians understand protein structures and identify drug targets. Edge AI enables remote patient monitoring—portable devices analyze heart rhythms in real time, improving response times and protecting data.
AI transforms the financial sector by enhancing fraud detection, credit scoring, and algorithmic trading. Darktrace spots anomalies in real time; Numeral Signals uses crowdsourced data for investment predictions; Upstart AI improves credit decisions, allowing inclusive lending. Clarifai’s model orchestration can integrate real‑time inference into high‑throughput systems, while local runners ensure sensitive transaction data never leaves the organization.
Retailers leverage AI for personalized experiences, demand forecasting, and AI‑generated advertisements. Tools like Vue.ai, Lily AI, and Granify personalize shopping and optimize conversions. Amazon Go’s Just Walk Out technology uses edge AI to enable cashierless shopping, processing video and sensor data locally. Clarifai’s vision models can analyze customer behavior in real time and generate context‑aware recommendations.
Educational platforms utilize AI to personalize learning paths, grade assignments, and provide tutoring. MagicSchool AI (2025 edition) plans lessons for teachers; Khanmigo by Khan Academy tutors students through conversation; Diffit helps educators tailor assignments. Clarifai’s NLP models can power intelligent tutoring systems that adapt in real time to a student’s comprehension level.
Manufacturers use AI for predictive maintenance, robotics automation, and quality assurance. Bright Machines Microfactories simplify production lines; Instrumental.ai identifies defects; Vention MachineMotion 3 enables adaptive robots. The Stream Analyze case study shows that deploying edge AI directly on the production line (using a Raspberry Pi) improved inspection speed 100‑fold and maintained data security.
As AI matures, several trends are reshaping model development and deployment. Understanding these trends helps ensure your models remain relevant, efficient, and responsible.
Building AI models is challenging; awareness of potential pitfalls enables you to proactively mitigate them.
A startup built an AI model to predict stock price movements using a small dataset. Initially, the model achieved 99 % accuracy on training data but only 60 % on the test set—classic over‑fitting. They fixed the issue by adding dropout layers, using early stopping, regularizing parameters, and collecting more data. They also simplified the architecture and implemented k‑fold cross‑validation to ensure robust performance.
Creating an AI model is a journey that spans strategic planning, data mastery, algorithmic expertise, robust engineering, ethical responsibility, and continuous improvement. Clarifai can help you on this journey with tools for compute orchestration, pretrained models, workflow management, and edge deployments. As AI continues to evolve—embracing multimodal interactions, autonomous agents, green computing, and federated intelligence—practitioners must remain adaptable, ethical, and visionary. By following this comprehensive guide and keeping an eye on emerging trends, you’ll be well‑equipped to build AI models that not only perform but also inspire trust and deliver real value.
Q1: How long does it take to build an AI model?
Building an AI model can take anywhere from a few weeks to several months, depending on the complexity of the problem, the availability of data, and the team’s expertise. A simple classification model might be up and running within days, while a robust, production‑ready system that meets compliance and fairness requirements could take months.
Q2: What programming language should I use?
Python is the most popular language for AI due to its extensive libraries and community support. Other options include R for statistical analysis, Julia for high performance, and Java/Scala for enterprise integration. Clarifai’s SDKs provide interfaces in multiple languages, simplifying integration.
Q3: How do I handle data privacy?
Use anonymization, encryption, and access controls. For collaborative training, consider federated learning, which trains models across devices without sharing raw data. Clarifai’s platform supports secure data handling and local inference.
Q4: What is the difference between machine learning and generative AI?
Machine learning focuses on recognizing patterns and making predictions, whereas generative AI creates new content (text, images, music) based on learned patterns. Generative models like transformers and diffusion models are particularly useful for creative tasks and data augmentation.
Q5: Do I need expensive hardware to build an AI model?
Not always. You can start with cloud‑based services or pretrained models. For large models, GPUs or specialized hardware improve training efficiency. Clarifai’s compute orchestration dynamically allocates resources, and local runners enable on‑device inference without costly cloud usage.
Q6: How do I ensure my model remains accurate over time?
Implement continuous monitoring for performance metrics and data drift. Use automated retraining pipelines and schedule regular audits for fairness and bias. MLOps tools make these processes manageable.
Q7: Can AI models be creative?
Yes. Generative AI creates text, images, video, and even 3D environments. Combining retrieval‑augmented generation with specialized AI agents results in highly creative and contextually aware systems.
Q8: How do I integrate Clarifai into my AI workflow?
Clarifai provides APIs and SDKs for model training, inference, workflow orchestration, data annotation, and edge deployment. You can fine‑tune Clarifai’s pretrained models or bring your own. The platform handles compute orchestration and allows you to run models on local runners for low‑latency, secure inference.
Q9: What trends should I watch in the near future?
Keep an eye on multimodal AI, federated learning, autonomous agents, green AI, quantum and neuromorphic hardware, and the growing open‑source ecosystem. These trends will shape how models are built, deployed, and managed.
Artificial intelligence is no longer just a buzzword; it is a central force reshaping industries, economies and everyday life. Yet with so much hype and jargon, it is easy to lose sight of what AI can really do today versus what might come tomorrow. That is why understanding the three types of AI—narrow, general and super—alongside functional categories like reactive machines and limited‑memory systems is important. These classifications help clarify capabilities, manage expectations and highlight the ethical implications of AI’s rapid progress. They also underpin regulatory debates and investment decisions, with AI attracting $33.9 billion in private investment in 2024 and more than 78 % of organisations using AI.
In this article you will find a deep dive into each AI type, real‑world examples, expert opinions, emerging trends and practical comparisons. We will also explore subtle differences between capability‑based and functional classifications, highlight the latest industry insights and show how Clarifai’s platform empowers organisations to build and deploy AI responsibly.
Let’s unpack each topic in detail.

Artificial Narrow Intelligence refers to AI systems designed to perform a specific task or a narrow range of tasks. These systems excel within their domain but cannot generalise beyond it. A recommendation engine that suggests movies on your favourite streaming service, a chatbot that answers banking queries or a self‑driving car’s lane‑keeping module are all examples of ANI. Because ANI focuses on specialised tasks, it accounts for nearly all AI deployed today, from smartphone assistants to industrial automation.
Researchers note that most current AI falls into the reactive or limited‑memory categories—two functional subtypes where systems respond to inputs with pre‑programmed rules or rely on short‑term memory. These align closely with ANI and emphasise that our everyday AI is still far from human‑like cognition.
Reactive machines are the simplest form of AI; they have no memory and respond directly to current inputs. IBM’s Deep Blue chess computer is a classic example: it evaluates the board’s current state and selects the best move based solely on rules and heuristics. Limited‑memory systems extend this by learning from past data to improve performance—a feature used in self‑driving cars that collect sensor data to make lane‑keeping or braking decisions.
In medical diagnostics, limited‑memory AI analyses large datasets of images and patient records to detect tumours or predict disease progression. These models do not understand the concept of “health” but excel at pattern recognition within a specific task.
ANI’s strength lies in precision and efficiency—machines can outperform humans at repetitive, data‑driven tasks such as parsing radiology images or identifying fraudulent transactions. However, ANI lacks general reasoning and cannot adapt to tasks outside its domain. This narrow focus also makes ANI vulnerable to bias and hallucination, as models sometimes generate plausible but inaccurate responses when asked about unfamiliar topics. Retrieval‑augmented generation (RAG) mitigates these issues by grounding models in verified knowledge bases.
ANI powers much of our digital world, from voice assistants to customer‑service bots. Clarifai’s platform makes it easier to build and deploy ANI applications at scale, offering compute orchestration and model inference capabilities that accelerate development cycles. For instance, developers can train custom image‑recognition models on Clarifai using local runners, then orchestrate them across cloud or on‑device environments for real‑time inference. This flexibility helps organisations integrate AI without massive infrastructure investments.
Artificial General Intelligence describes an AI system capable of understanding, learning and applying knowledge across multiple domains at a level comparable to a human being. Unlike ANI, AGI would exhibit flexibility and adaptability to perform any intellectual task, from solving math problems to composing music, without being explicitly programmed for each task. No AGI exists today; it remains a research milestone that inspires both excitement and skepticism.
Recent advances hint at AGI’s building blocks. Large language models (LLMs) like GPT‑4 and Gemini demonstrate emergent reasoning capabilities, while reasoning‑centric models such as o3 and Opus 4 can follow logical chains to solve multi‑step problems. These models operate on curated or synthetic datasets that emphasise reasoning, highlighting that training quality—not just scale—matters. Another promising avenue is multimodal AI, where models process text, images, audio and video together. Such integration brings machines closer to human‑like perception and may be essential for AGI.
Creating AGI isn’t just an engineering problem; it is also an ethical and philosophical challenge. Researchers must overcome obstacles like common‑sense reasoning, long‑term memory and energy efficiency. Equally important are alignment and safety: how do we ensure AGI respects human values and doesn’t act against our interests? Regulatory bodies worldwide have begun to address these questions, with legislative mentions of AI rising more than 21 % across 75 countries.
AGI would likely incorporate theory‑of‑mind capabilities—recognising emotions, intentions and social cues. Current research explores multimodal data to model human behaviours in healthcare and education. True self‑awareness, however, remains speculative. If achieved, AGI could not only understand others but also possess a sense of “self,” opening a new realm of ethical and philosophical questions.
While AGI is a distant goal, Clarifai supports researchers by providing a versatile platform for experimentation. With compute orchestration, scientists can test different neural architectures and training regimens across cloud and edge environments. Clarifai’s model hub allows easy access to state‑of‑the‑art LLMs and vision models, enabling experiments with multimodal data and reasoning‑centric algorithms. Local runners ensure data privacy and reduce latency, essential for projects exploring long‑term memory and contextual reasoning.
Artificial Super Intelligence refers to a theoretical AI that surpasses human intelligence in every domain—creativity, reasoning, emotional intelligence and social skills. ASI is common in science fiction, where machines gain self‑awareness and outsmart their creators. In reality, ASI remains purely speculative; its existence depends on overcoming the monumental challenge of AGI and then further self‑improving beyond human capabilities.
ASI could solve complex global problems, optimise resources and innovate at an unprecedented pace. However, the very qualities that make ASI powerful also pose existential risks: misaligned objectives, loss of control and unforeseen consequences. Ethicists and futurists urge proactive governance and research into AI alignment to ensure any future superintelligence acts in humanity’s best interests.
Some experts argue that ASI may never exist due to physical, computational or ethical constraints. Others believe that if AGI is achieved, runaway intelligence could lead to ASI. Regardless of stance, most agree that discussing ASI’s potential today helps shape responsible AI policies and fosters public awareness.
Clarifai promotes responsible AI practices by offering tools that support transparency, auditability and bias mitigation. Their model inference platform includes explainability features that help developers understand model decisions—an essential component for preventing misuse as AI systems become more sophisticated. Clarifai also partners with academic and policy institutions to foster ethical guidelines and support research on AI safety.
While capability‑based categories (ANI, AGI, ASI) describe what AI can do, functional classification explains how AI works. The four levels—reactive machines, limited‑memory systems, theory‑of‑mind AI and self‑aware AI—map a cognitive evolution path. Understanding these stages clarifies why most existing AI is still narrow and highlights milestones required for AGI.
Reactive machines respond to current inputs without memory. Examples include IBM’s Deep Blue, which calculated chess moves based on the board’s current state. These systems excel at fast, predictable tasks but cannot learn from experience.
Most modern AI falls into the limited‑memory category, where models leverage past data to improve decisions. Self‑driving cars use sensor data and historical information to navigate; voice assistants like Siri and Alexa adapt to user preferences over time. In healthcare, limited‑memory AI analyses patient histories and imaging to assist with diagnostics.
Theory‑of‑mind AI aims to recognise human emotions, intentions and social cues. Research in this area explores multimodal data—combining facial expressions, voice tone and body language—to enable machines to respond empathetically. While prototypes exist in labs, there are no commercially deployed theory‑of‑mind systems yet.
Self‑aware AI would possess consciousness and a sense of self. Although some humanoid robots, like “Sophia,” mimic self‑awareness through scripted responses, true self‑aware AI is purely speculative. Achieving this stage would require breakthroughs in neuroscience, philosophy and AI safety.
Clarifai supports functional AI development at all levels. For reactive machines and limited‑memory systems, Clarifai offers out‑of‑the‑box models for vision, language and audio that can be fine‑tuned using local runners and deployed across cloud or on‑device environments. Researchers exploring theory‑of‑mind can leverage Clarifai’s multimodal training tools, combining data from images, audio and text. While self‑aware AI remains theoretical, Clarifai’s ethics initiatives encourage dialogue on responsible innovation.

Agentic AI refers to systems that act autonomously toward a goal, breaking tasks into sub‑tasks and adapting as conditions change. Unlike chatbots that wait for the next prompt, agentic AI operates like a junior employee—executing multi‑step workflows, accessing tools and making decisions. Current industry reports describe how agents perform HR onboarding, password resets, meeting scheduling and internal analytics. In the near future, agents could monitor finances, generate marketing content or manage e‑commerce recovery tasks.
Clarifai’s platform enables agentic AI by orchestrating multiple models and tools. Developers can use Clarifai’s workflow builder to chain models (e.g., summarisation, classification, sentiment analysis) and integrate external APIs for data retrieval or action execution. This modular approach supports rapid prototyping and deployment of AI agents that can operate autonomously yet remain under human control.
Multimodal AI processes multiple data types—text, images, audio and video—within a single model, bringing machines closer to human‑like understanding. Recent models such as GPT‑4.1 and Gemini 2.0 can interpret images, listen to voice notes and analyse text simultaneously. This capability has transformative potential in healthcare—combining radiology images with patient records for comprehensive diagnostics—and in sectors like e‑commerce and customer support.
Clarifai offers multimodal pipelines that allow developers to build applications combining visual, audio and text data. For instance, an insurance claims app could use Clarifai’s computer vision model to assess damage from photos and a language model to process claim narratives.
Reasoning‑centric models emphasise logic and step‑by‑step reasoning rather than mere pattern recognition. Advancements in models like o3 and Opus 4 allow AI to solve complex tasks, such as financial analysis or logistics optimisation, by breaking down problems into logical steps. Smaller models like Microsoft’s Phi‑2 achieve strong reasoning using curated datasets focused on quality rather than quantity.
Clarifai’s experimentation environment supports training and evaluating reasoning‑centric models. Developers can plug in curated datasets, fine‑tune models and benchmark them against tasks requiring logical inference. Clarifai’s explainability tools aid debugging by revealing the reasoning steps behind model outputs.
Model Context Protocol (MCP) is an open standard that allows AI agents to connect to external systems (files, tools, APIs) in a consistent, secure way. It acts like a universal port for AI, facilitating plug‑and‑play architecture. Instead of writing bespoke integrations, developers use MCP to give agents access to file systems, terminals or databases, enabling multi‑step workflows.
Clarifai’s workflow builder is compatible with MCP principles. Users can design modular pipelines where an AI model reads data from a database, processes it and writes results back, all within a consistent interface. This modularity makes scaling and maintenance easier.
Retrieval‑Augmented Generation (RAG) combines language models with external knowledge bases to deliver grounded, accurate responses. Instead of relying solely on pre‑training, RAG systems index documents (policies, manuals, datasets) and retrieve relevant snippets to feed into the model during inference. This reduces hallucinations and ensures answers are up‑to‑date.
Clarifai offers RAG‑enabled workflows that connect language models to company knowledge bases. Developers can build custom retrieval engines, index internal documents and integrate them with generative models, all managed through Clarifai’s platform.
On‑device AI shifts inference from the cloud to local devices equipped with neural processing units (NPUs), enhancing privacy, reducing latency and lowering costs. Recent hardware like Qualcomm’s Snapdragon X Elite and Apple’s M‑series chips enable models with over 13 billion parameters to run on laptops or mobile devices. This trend enables offline functionality and real‑time responsiveness.
Clarifai’s local runners support on‑device deployment, allowing developers to run vision and language models directly on edge devices. A hybrid option lets simple tasks execute locally while more complex reasoning is offloaded to the cloud.
Compact models offer a practical alternative to giant LLMs by focusing on specific tasks with fewer parameters. Examples include Phi‑3.5‑mini, Mixtral 8×7B and TinyLlama. These models perform well when fine‑tuned for narrow domains, require less computation and can be deployed on edge devices or embedded systems.
Clarifai supports training, fine‑tuning and deployment of compact models. This makes AI accessible to organisations without massive compute resources and allows quick prototyping for domain‑specific tasks.
Public and governmental engagement with AI is growing rapidly. Legislative mentions of AI doubled in 2024 and investments surged, with countries like Canada committing $2.4 billion and Saudi Arabia pledging $100 billion. Public sentiment varies: a majority in China and Indonesia view AI as beneficial, while skepticism remains higher in the US and Canada. Regulations aim to ensure responsible deployment, address privacy concerns and mitigate harms like deepfakes.
Clarifai engages with regulators and industry groups to shape ethical guidelines. The platform includes tools for bias detection and compliance documentation, helping organisations meet emerging regulatory requirements.

|
AI Type |
Scope |
Current Status |
Examples |
Key Considerations |
|
ANI (Narrow AI) |
Performs specific tasks; cannot generalise |
Ubiquitous; powers most current AI systems |
Recommendation engines, chatbots, self‑driving cars |
High accuracy within narrow domains; limited creativity and reasoning |
|
AGI (General AI) |
Matches human cognitive abilities across domains |
Not yet achieved; active research area |
Hypothetical (future advanced multimodal models) |
Requires reasoning, long‑term memory and alignment; ethical and technical challenges |
|
ASI (Super AI) |
Surpasses human intelligence in all domains |
Purely speculative |
Fictional AI characters (e.g., HAL 9000) |
Raises existential risks and alignment concerns; spurs ethical debate |
|
Functional Type |
Corresponding Capability |
Characteristics |
|
Reactive Machines |
ANI |
Rule‑based, no memory; e.g., Deep Blue |
|
Limited‑Memory Systems |
ANI |
Learn from past data; used in self‑driving cars and medical imaging |
|
Theory‑of‑Mind AI |
Towards AGI |
Model human emotions and intentions; research stage |
|
Self‑Aware AI |
ASI |
Possess consciousness; purely hypothetical |
 Real‑World Implications and Case Studies
Real‑World Implications and Case StudiesSelf‑driving cars exemplify limited‑memory AI. They collect data from sensors (cameras, lidar, radar) and historical drives to make decisions on steering, braking and lane changes. While they demonstrate impressive capabilities, accidents highlight the need for better edge‑case handling and ethical decision‑making. Integrating RAG with driving data could improve situational awareness by referencing additional sources, such as road‑work updates or dynamic traffic rules.
AI models assist radiologists in detecting diseases such as cancer by analysing medical images and patient histories. These systems enhance accuracy and speed, but also require rigorous validation and bias monitoring. Clarifai’s compute orchestration enables hospitals to deploy such models locally, ensuring data privacy and reducing latency. For example, a rural clinic can run a model on a local device to analyse X‑rays, then send anonymised results for further consultation.
Imagine an agentic AI deployed in a mid‑sized company’s HR department. The agent autonomously handles employee onboarding: creating accounts, scheduling training sessions and answering policy questions using a knowledge base. It also manages IT requests, resetting passwords and troubleshooting basic issues. Within months, the agent reduces onboarding time by 40 % and decreases ticket resolution time by 30 %. Using Clarifai’s workflow builder, the company chains multiple models (document classification, summarisation, scheduling) and integrates them with internal HR software through an MCP‑like protocol.
California’s AI regulations illustrate the evolving policy landscape. New laws introduced in January 2025 protect user privacy, healthcare data and victims of deepfakes. Globally, legislative mentions of AI increased by 21 %, and countries invested billions to foster responsible AI. Organisations using AI must adapt to these regulations by implementing bias detection, transparency and compliance features—capabilities that Clarifai’s platform provides.
 Future Outlook & Conclusion
Future Outlook & ConclusionAs we progress into the second half of the decade, AI’s influence will only grow. Expect agentic AI to become mainstream, multimodal models to power more natural interactions and on‑device AI to bring intelligence closer to users. Reasoning‑centric models will continue to improve, narrowing the gap between narrow AI and the dream of AGI. Compact models will proliferate, making AI accessible in resource‑constrained environments. Meanwhile, public investments and regulations will shape AI’s trajectory, emphasising responsible innovation and ethical considerations. By understanding the three types of AI and the functional categories, individuals and organisations can navigate this evolving landscape more effectively. With platforms like Clarifai providing powerful tools, the journey from narrow to more general intelligence becomes more accessible—yet always demands vigilance to ensure AI benefits society.
The three capability‑based categories are Artificial Narrow Intelligence (ANI), designed for specific tasks; Artificial General Intelligence (AGI), a research goal aiming to match human cognition; and Artificial Super Intelligence (ASI), a hypothetical level where machines surpass human intelligence.
Reactive machines and limited‑memory systems correspond to ANI, handling specific tasks with or without short‑term memory. Theory‑of‑mind AI, which would understand emotions and social cues, points towards AGI. Self‑aware AI, currently hypothetical, would be necessary for ASI.
Not yet. While large language models and reasoning‑centric approaches show progress, AGI remains hypothetical. Researchers still need breakthroughs in common‑sense reasoning, long‑term memory and alignment.
RAG improves AI accuracy by pulling relevant information from a knowledge base before generating responses. This reduces hallucinations and ensures answers are grounded in up‑to‑date data.
On‑device AI runs models locally on devices equipped with NPUs, enhancing privacy and reducing latency. Cloud AI relies on remote servers. Hybrid approaches combine both for optimal performance.
Clarifai provides a comprehensive platform for building, training and deploying AI models. It offers compute orchestration, model inference, multimodal pipelines, RAG workflows and ethics tools. Whether you’re developing narrow AI applications or experimenting with advanced reasoning, Clarifai’s platform supports your journey while emphasising responsible use.
MAICON brings together top visionaries and experts in the field of AI during a three-day conference packed with actionable sessions and networking events—all to position you as the change agent your organization (and career) needs. In this ongoing speaker series, we’re featuring these extraordinary leaders, with forward-looking predictions, actionable tips you can use today, and a preview of their MAICON 2025 sessions. Continue reading “How to Protect Your Brand in an AI-Powered World with Jen Leonard [MAICON 2025 Speaker Series]”
MAICON brings together top visionaries and experts in the field of AI during a three-day conference packed with actionable sessions and networking events—all to position you as the change agent your organization (and career) needs. In this ongoing speaker series, we’re featuring these extraordinary leaders, with forward-looking predictions, actionable tips you can use today, and a preview of their MAICON 2025 sessions. Continue reading “How to Make AI Your Smartest Business Strategist with Jen Taylor [MAICON 2025 Speaker Series]”
Large language models (LLMs) have revolutionized how machines understand and generate text, but their inference workloads come with substantial computational and memory costs. Whether you’re scaling chatbots, deploying summarization tools or integrating generative AI into enterprise workflows, optimizing inference is crucial for cost control and user experience. Due to the enormous parameter counts of state-of-the-art models and the mixed compute‑ and memory‑bound phases involved, naive deployment can lead to bottlenecks and unsustainable energy consumption. This article from Clarifai—a leader in AI platforms—offers a deep, original dive into techniques that minimize latency, reduce costs and ensure reliable performance across GPU, CPU and edge environments.
We’ll explore the architecture of LLM inference, core challenges like memory bandwidth limitations, batching strategies, multi‑GPU parallelization, attention and KV cache optimizations, model‑level compression, speculative and disaggregated inference, scheduling and routing, metrics, frameworks and emerging trends. Each section includes a Quick Summary, in‑depth explanations, expert insights and creative examples to make complex topics actionable and memorable. We’ll also highlight how Clarifai’s orchestrated inference pipelines, flexible model deployment and compute runners integrate seamlessly with these techniques. Let’s begin our journey toward building scalable, cost‑efficient LLM applications.
Below is a snapshot of the key takeaways you’ll encounter in this guide. Use it as a cheat sheet to grasp the overall narrative before diving into each section.
Ready to optimize your LLM inference? Let’s dive into each section.
What happens under the hood of LLM inference? LLM inference comprises two distinct phases—prefill and decode—within a transformer architecture. Prefill processes the entire prompt in parallel and is compute‑bound, while decode generates one token at a time and is memory‑bound due to key‑value (KV) caching.
Large language models like GPT‑3/4 and Llama are decoder‑only transformers, meaning they use only the decoder portion of the transformer architecture to generate text. Transformers rely on self‑attention to compute token relationships, but decoding in these models happens sequentially: each generated token becomes input for the next step. Two key phases define this process—prefill and decode.
In the prefill phase, the model encodes the entire input prompt in parallel; this is compute‑bound and benefits from GPU utilization because matrix multiplications are batched. The model loads the entire prompt into the transformer stack, calculating activations and initial key‑value pairs for attention. Hardware with high compute throughput—like NVIDIA H100 GPUs—excels in this stage. During prefill, memory usage is dominated by activations and weight storage, but it’s manageable compared to later stages.
Decode occurs after the prefill stage, producing one token at a time; each token’s computation depends on all previous tokens, making this phase sequential and memory‑bound. The model retrieves cached key‑value pairs from previous steps and appends new ones for each token, meaning memory bandwidth—not compute—limits throughput. Because the model cannot parallelize across tokens, GPU cores often idle while waiting for memory fetches, causing underutilization. As context windows grow to 8K, 16K or more, the KV cache becomes enormous, accentuating this bottleneck.
LLM inference uses three primary memory components: model weights (fixed parameters), activations (intermediate outputs) and the KV cache (past key‑value pairs stored for self‑attention). Activations are large during prefill but small in decode; the KV cache grows linearly with context length and layers, making it the main memory consumer. For example, a 7B model with 4,096 tokens and half‑precision weights may require around 2 GB of KV cache per batch.
Imagine an assembly line where the first stage stamps all parts at once (prefill) and the second stage assembles them sequentially (decode). If the assembly stage’s worker must fetch each part from a distant warehouse (KV cache), he will wait longer than the stamping stage, causing a bottleneck. This analogy highlights why decode is slower than prefill and underscores the importance of optimizing memory access.
Clarifai’s inference engine automatically manages prefill and decode stages across GPUs and CPUs, abstracting away complexity. It supports streaming token outputs and memory‑efficient caching, ensuring that your models run at peak utilization while reducing infrastructure costs. By leveraging Clarifai’s compute orchestration, you can optimize the entire inference pipeline with minimal code changes.

Which bottlenecks make LLM inference expensive and slow? Major challenges include huge memory footprints, long context windows, inefficient routing, absent caching, and sequential tool execution; these issues inflate latency and cost.
The sheer size of modern LLMs—often tens of billions of parameters—means that storing and moving weights, activations and KV caches across memory channels becomes a central challenge. As context windows grow to 8K, 32K or even 128K tokens, the KV cache scales linearly, demanding more memory and bandwidth. If memory capacity is insufficient, the model may swap to slower memory tiers (e.g., CPU or disk), drastically increasing latency.
Detailed latency analyses show that inference time includes model loading, tokenization, KV‑cache prefill, decode and output processing. Model loading is a one‑time cost when starting a container but becomes significant when frequently spinning up instances. Prefill latency includes running FlashAttention to compute attention across the entire prompt, while decode latency includes retrieving and storing KV cache entries. Output processing (detokenization and result streaming) adds overhead as well.
A critical yet overlooked factor is model routing: sending every user query to a large model—like a 70B parameter LLM—when a smaller model would suffice wastes compute and increases cost. Routing strategies that select the right model for the task (e.g., summarization vs. math reasoning) can cut costs dramatically. Equally important is caching: not storing or deduplicating identical prompts leads to redundant computations. Semantic caching and prefix caching can reduce costs by up to 90%.
Another challenge arises when LLM outputs depend on external tools or APIs—retrieval, database queries or summarization pipelines. If these calls execute sequentially, they block the next steps and increase latency. Parallelizing independent API calls and orchestrating concurrency improves throughput. However, orchestrating concurrency manually across microservices is error‑prone.
Inefficient inference not only slows responses but also consumes more energy and increases carbon emissions, raising sustainability concerns. As LLM adoption grows, optimizing inference becomes essential to maintain environmental stewardship. By minimizing wasted cycles and memory transfers, you reduce both operational expenses and the carbon footprint.
Clarifai’s workflow automation enables dynamic model routing by analyzing the user’s query and selecting an appropriate model from your deployment library. With built‑in semantic caching, identical or similar requests are served from cache, reducing unnecessary compute. Clarifai’s orchestration layer also parallelizes external tool calls, ensuring your application remains responsive even when integrating multiple APIs.
How can batching reduce latency and cost? Batching combines multiple inference requests into a single GPU pass, amortizing computation and memory overhead; static, dynamic and in‑flight batching approaches balance throughput and fairness.
Static batching groups requests of similar length into a single batch and processes them together; this improves throughput because matrix multiplications operate on larger matrices with better GPU utilization. However, static batches suffer from head‑of‑line blocking: the longest request delays all others because the batch cannot finish until all sequences complete. This is particularly problematic for interactive applications where some users wait longer due to other users’ long inputs.
To address static batching limitations, dynamic or in‑flight batching allows new requests to enter a batch as soon as space becomes available; completed sequences are evicted, and tokens are generated for new sequences in the same batch. This continuous batching maximizes GPU utilization by keeping pipelines full while reducing tail latency. Frameworks like vLLM implement this strategy by managing the GPU state and KV cache for each sequence, ensuring that memory is reused efficiently.
When a model is split across multiple GPUs using pipeline parallelism, micro‑batching further improves utilization by dividing a batch into smaller micro‑batches that traverse pipeline stages simultaneously. Although micro‑batching introduces some overhead, it reduces pipeline bubbles—periods where some GPUs are idle because other stages are processing. This strategy is important for large models that require pipeline parallelism for memory reasons.
Batch size has a direct impact on latency and throughput: larger batches achieve higher throughput but increase per‑request latency. Benchmark studies reveal that a 7B model’s latency can drop from 976 ms at batch size 1 to 126 ms at batch size 8, demonstrating the benefit of batching. However, excessively large batches lead to diminishing returns and potential timeouts. Dynamic scheduling algorithms can determine optimal batch sizes based on queue length, model load and user‑defined latency targets.
Imagine an airport shuttle bus waiting for passengers: a static shuttle leaves only when full, causing passengers to wait; dynamic shuttles continuously pick up passengers as seats free up, reducing overall waiting time. Similarly, in‑flight batching ensures that short requests aren’t held hostage by long ones, improving fairness and resource usage.
Clarifai’s inference management automatically implements dynamic batching; it groups multiple user queries and adjusts batch sizes based on real‑time queue statistics. This ensures high throughput without sacrificing responsiveness. Furthermore, Clarifai allows you to configure micro‑batch sizes and scheduling policies, giving you fine‑grained control over latency‑throughput trade‑offs.

How can multiple GPUs accelerate large LLMs? Model parallelization distributes a model’s weights and computation across GPUs to overcome memory limits; techniques include pipeline parallelism, tensor parallelism and sequence parallelism.
Single GPUs may not have enough memory to host a large model; splitting the model across multiple GPUs allows you to scale beyond a single device’s memory footprint. Parallelism also helps reduce inference latency by distributing computations across multiple GPUs; however, the choice of parallelism technique determines the efficiency.
Pipeline parallelism divides the model into stages—layers or groups of layers—and assigns each stage to a different GPU. Each micro‑batch sequentially moves through these stages; while one GPU processes micro‑batch i, another can start processing micro‑batch i+1, reducing idle time. However, there are ‘pipeline bubbles’ when early GPUs finish processing and wait for later stages; micro‑batching helps mitigate this. Pipeline parallelism suits deep models with many layers.
Tensor parallelism shards the computations within a layer across multiple GPUs: for example, matrix multiplications are split horizontally (column) or vertically (row) across GPUs. This approach requires synchronization for operations like softmax, layer normalization and dropout, so communication overhead can become significant. Tensor parallelism works best for extremely large layers or for implementing multi‑GPU matrix multiply operations.
Sequence parallelism divides work along the sequence dimension; tokens are partitioned among GPUs, which compute attention independently on different segments. This reduces memory pressure on any single GPU because each handles only a portion of the KV cache. Sequence parallelism is less common but useful for long sequences and models optimized for memory efficiency.
In practice, large LLMs often use hybrid strategies combining pipeline and tensor parallelism—e.g., using pipeline parallelism for high‑level model partitioning and tensor parallelism within layers. Choosing the right combination depends on model architecture, hardware topology and batch size. Frameworks like DeepSpeed and Megatron handle these complexities and automate partitioning.
Clarifai’s infrastructure supports multi‑GPU deployment using both pipeline and tensor parallelism; its orchestrator automatically partitions models based on GPU memory and interconnect bandwidth. By using Clarifai’s multi‑GPU runner, you can serve 70B or larger models on commodity clusters without manual tuning.
How can we reduce the overhead of self‑attention? Optimizations include multi‑query and grouped‑query attention, FlashAttention for improved memory locality and FlashInfer for block‑sparse operations and JIT‑compiled kernels.
Transformers compute attention by comparing each token with every other token in the sequence (scaled dot‑product attention). This requires computing queries (Q), keys (K) and values (V) and then performing a softmax over the dot products. Attention is expensive because the operation scales quadratically with sequence length and involves frequent memory reads/writes, causing high latency during inference.
Standard multi‑head attention uses separate key and value projections for each head, which increases memory bandwidth requirements. Multi‑query attention reduces memory usage by sharing keys and values across multiple heads; grouped‑query attention further shares keys/values across groups of heads, balancing performance and accuracy. These approaches reduce the number of key/value matrices, decreasing memory traffic and improving inference speed. However, they may slightly reduce model quality; selecting the right configuration requires testing.
FlashAttention is a GPU kernel that reorders operations and fuses them to maximize on‑chip memory usage; it calculates attention by tiling the Q/K/V matrices and reducing memory reads/writes. The original FlashAttention algorithm significantly speeds up attention on A100 and H100 GPUs and is widely adopted in open‑source frameworks. It requires custom kernels but integrates seamlessly into PyTorch.
FlashInfer builds on FlashAttention with block‑sparse KV cache formats, JIT compilation and load‑balanced scheduling. Block‑sparse formats store KV caches in contiguous blocks rather than contiguous sequences, enabling selective fetches and lower memory fragmentation. JIT‑compiled kernels generate specialized code at runtime, optimizing for the current model configuration and sequence length. Benchmarks show FlashInfer reduces inter‑token latency by 29–69% and long‑context latency by 28–30%, speeding parallel generation by 13–17%.
Imagine a library where each book contains references to every other book; retrieving information requires cross‑referencing all these references (standard attention). If the library organizes references into groups that share index cards (MQA/GQA), librarians need fewer cards and can fetch information faster. FlashAttention is like reorganizing shelves so that books and index cards are adjacent, reducing walking time. FlashInfer introduces block‑based shelving and custom retrieval scripts that generate optimized retrieval instructions on the fly.
Clarifai’s inference runtime uses optimized attention kernels under the hood; you can select between standard MHA, MQA or GQA when training custom models. Clarifai also integrates with next‑generation attention engines like FlashInfer, providing performance gains without the need for manual kernel tuning. By leveraging Clarifai’s AI infrastructure, you gain the benefits of cutting‑edge research with a single configuration change.

What is the role of the KV cache in LLMs, and how can we optimize it? The KV cache stores past keys and values during inference; managing it efficiently through PagedAttention, compression and streaming is critical to reduce memory usage and fragmentation.
Self‑attention depends on all previous tokens; recomputing keys and values for each new token would be prohibitively expensive. The KV cache stores these computations so they can be reused, dramatically speeding up decode. However, caching introduces memory overhead: the size of the KV cache grows linearly with sequence length, number of layers and number of heads. This growth must be managed to avoid running out of GPU memory.
Each layer of a model has its own KV cache, and the total memory required is the sum across layers and heads; the formula is roughly: 2 * num_layers * num_heads * context_length * hidden_size * precision_size. For a 7B model, this can quickly reach gigabytes per batch. Static cache allocation leads to fragmentation when sequence lengths vary; memory allocated for one sequence may remain unused if that sequence ends early, wasting capacity.
PagedAttention divides the KV cache into fixed‑size blocks and stores them non‑contiguously in GPU memory; an index table maps tokens to blocks. When a sequence ends, its blocks can be recycled immediately by other sequences, minimizing fragmentation. This approach allows in‑flight batching where sequences of different lengths coexist in the same batch. PagedAttention is implemented in vLLM and other inference engines to reduce memory overhead.
Researchers are exploring compression techniques to reduce KV cache size, such as storing keys/values in lower precision or using delta encoding for incremental changes. Streaming cache approaches offload older tokens to CPU or disk and prefetch them when needed. These techniques trade compute for memory but enable longer context windows without scaling GPU memory linearly.
Clarifai’s model serving engine uses dynamic KV cache management to recycle memory across sessions; users can configure PagedAttention for improved memory efficiency. Clarifai’s analytics dashboard provides real‑time monitoring of cache hit rates and memory usage, enabling data‑driven scaling decisions. By combining Clarifai’s caching strategies with dynamic batching, you can handle more concurrent users without provisioning extra GPUs.

Which model modifications shrink size and accelerate inference? Model‑level optimizations include quantization, sparsity, knowledge distillation, mixture‑of‑experts (MoE) and parameter‑efficient fine‑tuning; these techniques reduce memory and compute requirements while retaining accuracy.
Quantization converts model weights and activations from 32‑bit or 16‑bit precision to lower bit widths such as 8‑bit or even 4‑bit. Lower precision reduces memory footprint and speeds up matrix multiplications, but may introduce quantization error if not applied carefully. Techniques like LLM.int8() target outlier activations to maintain accuracy while converting the bulk of weights to 8‑bit. Dynamic quantization adapts bit widths on the fly based on activation statistics, further reducing error.
Sparsity prunes redundant or near‑zero weights in neural networks; structured sparsity removes entire blocks or groups of weights (e.g., 2:4 sparsity means two of four weights in a group are zero). GPUs can accelerate sparse matrix operations, skipping zero elements to save compute and memory bandwidth. However, pruning must be done judiciously to avoid quality degradation; fine‑tuning after pruning helps recover performance.
Distillation trains a smaller ‘student’ model to mimic the outputs of a larger ‘teacher’ model. The student learns to approximate the teacher’s internal distributions rather than just final labels, capturing richer information. Notable results include DistilBERT and DistilGPT, which achieve about 97% of the teacher’s performance while being 40% smaller and 60% faster. Distillation helps deploy large models to resource‑constrained environments like edge devices.
MoE models contain multiple specialized expert sub‑models and a gating network that routes each token to one or a few experts. At inference time, only a fraction of parameters is active, reducing memory usage per token. For example, an MoE model with 20B parameters might activate only 3.6 B parameters per forward pass. MoE models can achieve quality comparable to dense models at lower compute cost, but they require sophisticated routing and may introduce load‑balancing challenges.
Methods like LoRA, QLoRA and adapters add lightweight trainable layers on top of frozen base models, enabling fine‑tuning with minimal additional parameters. PEFT reduces fine‑tuning overhead and speeds up inference by keeping the majority of weights frozen. It’s particularly useful for customizing large models to domain‑specific tasks without replicating the entire model.
Clarifai supports quantized and sparse model formats out of the box; you can load 8‑bit models and benefit from reduced latency without manual modifications. Our platform also provides tools for knowledge distillation, allowing you to distill large models into smaller variants suited for real‑time applications. Clarifai’s mixture‑of‑experts architecture enables you to route queries to specialized sub‑models, optimizing compute usage for diverse tasks.
What are speculative and disaggregated inference, and how do they improve performance? Speculative inference uses a cheap draft model to generate multiple tokens in parallel, which the main model then verifies; disaggregated inference separates prefill and decode phases across different hardware resources.
Speculative inference splits the decoding workload between two models: a smaller, fast ‘draft’ model generates a batch of token candidates, and the large ‘verifier’ model checks and accepts or rejects these candidates. If the verifier accepts the draft tokens, inference advances several tokens at once, effectively parallelizing token generation. If the draft includes incorrect tokens, the verifier corrects them, ensuring output quality. The challenge is designing a draft model that approximates the verifier’s distribution closely enough to achieve high acceptance rates.
The CoSine system extends speculative inference by decoupling drafting and verification across multiple nodes; it uses specialized drafters and a confidence‑based fusion mechanism to orchestrate collaboration. CoSine’s pipelined scheduler assigns requests to drafters based on load and merges candidates via a gating network; this reduces latency by 23% and increases throughput by 32% in experiments. CoSine demonstrates that speculative decoding can scale across distributed clusters.
Disaggregated inference runs the compute‑bound prefill phase on high‑end GPUs (e.g., cloud GPUs) and offloads the memory‑bound decode phase to cheaper, memory‑optimized hardware closer to end users. This architecture reduces end‑to‑end latency by minimizing network hops for decode and leverages specialized hardware for each phase. For example, large GPU clusters perform the heavy lifting of prefill, while edge devices or CPU servers handle sequential decode, streaming tokens to users.
Speculative inference adds complexity by requiring a separate draft model; tuning draft accuracy and acceptance thresholds is non‑trivial. If acceptance rates are low, the overhead may outweigh benefits. Disaggregated inference introduces network communication costs between prefill and decode nodes; reliability and synchronization become critical. Nonetheless, these approaches represent innovative ways to break the sequential bottleneck and bring inference closer to the user.
Clarifai is researching speculative inference as part of its upcoming inference innovations; our platform will enable you to specify a draft model for speculative decoding, automatically handling acceptance thresholds and fallback mechanisms. Clarifai’s edge deployment capabilities support disaggregated inference: you can run prefill in the cloud using high‑performance GPUs and decode on local runners or mobile devices. This hybrid architecture reduces latency and data transfer costs, delivering faster responses to your end users.
How can smart scheduling and routing improve cost and latency? Request scheduling predicts decode lengths and groups similar requests, dynamic routing assigns tasks to appropriate models, and caching reduces duplicate computation.
Scheduling systems can predict the number of tokens a request will generate (decode length) based on historical data or model heuristics. Shorter requests are prioritized to minimize overall queue time, reducing tail latency. Dynamic batch managers adjust groupings based on predicted lengths, achieving fairness and maximizing throughput. Predictive scheduling also helps allocate memory for the KV cache, avoiding fragmentation.
Different tasks have varying complexity: summarizing a short paragraph may require a small 3B model, while complex reasoning might need a 70B model. Smart routing matches requests to the smallest sufficient model, reducing computation and cost. Routing can be rule‑based (task type, input length) or learned via meta‑models that estimate quality gains. Multi‑model orchestration frameworks enable seamless fallbacks if a smaller model fails to meet quality thresholds.
Caching identical or similar requests avoids redundant computations; caching strategies include exact match caching (hashing prompts), semantic caching (embedding similarity) and prefix caching (storing partial KV caches). Semantic caching allows retrieval of answers for paraphrased queries; prefix caching stores KV caches for common prefixes in chat applications, allowing multiple sessions to share partial computations. Combined with routing, caching can cut costs by up to 90%.
Streaming outputs tokens as soon as they’re generated rather than waiting for the entire output improves perceived latency and allows user interaction while the model continues generating. Streaming reduces “time to first token” (TTFT) and keeps users engaged. Inference engines should support token streaming alongside dynamic batching and caching.
When retrieval‑augmented generation is used, compressing context via summarization or passage selection reduces the number of tokens passed to the model, saving compute. GraphRAG builds knowledge graphs from retrieval results to improve retrieval accuracy and reduce redundancy. By reducing context lengths, you lighten memory and latency load during inference.
LLM outputs often depend on external tools or APIs (e.g., search, database queries, summarization); orchestrating these calls in parallel reduces sequential waiting time. Frameworks like Clarifai’s Workflow API support asynchronous tool execution, ensuring that the model doesn’t idle while waiting for external data.
Clarifai offers built‑in decode length prediction and batch scheduling to optimize queueing; our smart router assigns tasks to the most suitable model, reducing compute costs. With Clarifai’s caching layer, you can enable semantic and prefix caching with a single configuration, drastically cutting costs. Streaming is enabled by default in our inference API, and our workflow orchestration executes independent tools concurrently.
Which metrics define success in LLM inference? Key metrics include time to first token (TTFT), time between tokens (TBT), tokens per second, throughput, P95/P99 latency and memory usage; monitoring token usage, cache hits and tool execution time yields actionable insights.
Time to first token (TTFT) measures the delay between sending a request and receiving the first output token; it is influenced by model loading, tokenization, prefill and scheduling. Time between tokens (TBT) measures the interval between consecutive output tokens; it reflects decode efficiency. Tokens per second (TPS) is the reciprocal of TBT and indicates throughput. Monitoring TTFT and TPS helps optimize both prefill and decode phases.
Average latency can hide tail performance issues; therefore, tracking P95 and P99 latency—where 95% or 99% of requests finish faster—is crucial to ensure consistent user experience. Throughput measures the number of requests or tokens processed per unit time; high throughput is essential for serving many users concurrently. Capacity planning should consider both throughput and tail latency to prevent overload.
CPU and GPU utilization metrics show how efficiently hardware is used; low GPU utilization in decode may signal memory bottlenecks, while high CPU usage may indicate bottlenecks in tokenization or tool execution. Memory usage, including KV cache occupancy, helps identify fragmentation and the need for compaction techniques.
In addition to hardware metrics, monitor token usage, cache hit ratios, retrieval latencies and tool execution times. High cache hit rates reduce compute cost; long retrieval or tool latency suggests a need for parallelization or caching external responses. Observability dashboards should correlate these metrics with user experience to identify optimization opportunities.
Open‑source tools like vLLM include built‑in benchmarking scripts for measuring latency and throughput across different models and batch sizes. KV cache calculators estimate memory requirements for specific models and sequence lengths. Integrating these tools into your performance testing pipeline ensures realistic capacity planning.
Clarifai’s analytics dashboard provides real‑time charts for TTFT, TPS, P95/P99 latency, GPU/CPU utilization, and cache hit rates. You can set alerts for SLO violations and automatically scale up resources when throughput threatens to exceed capacity. Clarifai also integrates with external observability tools like Prometheus and Grafana for unified monitoring across your stack.
What can we learn from real‑world LLM serving frameworks? Frameworks like vLLM, FlashInfer, TensorRT‑LLM and LMDeploy implement dynamic batching, attention optimizations, multi‑GPU parallelism and quantization; understanding their strengths helps choose the right tool for your application.
vLLM is an open‑source inference engine designed for high‑throughput LLM serving; it introduces continuous batching and PagedAttention to maximize GPU utilization. Continuous batching evicts completed sequences and inserts new ones, eliminating head‑of‑line blocking. PagedAttention partitions KV caches into fixed‑size blocks, reducing memory fragmentation. vLLM provides benchmarks showing low latency even at high batch sizes, with performance scaling across GPU clusters.
FlashInfer is a research project that builds upon FlashAttention; it employs block‑sparse KV cache formats and JIT compilation to optimize kernel execution. By using custom kernels for each sequence length and model configuration, FlashInfer reduces inter‑token latency by 29–69% and long‑context latency by 28–30%. It integrates with vLLM and other frameworks, offering state‑of‑the‑art performance improvements.
TensorRT‑LLM is an NVIDIA‑backed framework that converts LLMs into highly optimized TensorRT engines; it features dynamic batching, KV cache management and quantization support. TensorRT‑LLM integrates with the TensorRT library to accelerate inference on GPUs using low‑level kernels. It supports custom plugins for attention and offers fine‑grained control over kernel selection.
LMDeploy (formerly by Alibaba) focuses on serving LLMs using quantization and dynamic batching; it emphasizes compatibility with various hardware platforms and includes a runtime for CPU, GPU and AI accelerators. LMDeploy supports low‑bit quantization, enabling deployment on edge devices. It also integrates request routing and caching.
|
Framework |
Key Features |
Use Cases |
|
vLLM |
Continuous batching, PagedAttention, dynamic KV cache management |
High‑throughput GPU inference, dynamic workloads |
|
FlashInfer |
Block‑sparse KV cache, JIT kernels, integrated with vLLM |
Long‑context tasks, parallel generation |
|
TensorRT‑LLM |
TensorRT integration, quantization, custom plugins |
GPU optimization, low‑level control |
|
LMDeploy |
Quantization, dynamic batching, cross‑hardware support |
Edge deployment, CPU inference |
Clarifai integrates with vLLM and TensorRT‑LLM as part of its backend infrastructure; you can choose which engine suits your latency and hardware needs. Our platform abstracts away the complexity, offering you a simple API for inference while running on the most efficient engine under the hood. If your use case demands quantization or edge deployment, Clarifai automatically selects the appropriate backend (e.g., LMDeploy).
What innovations are shaping the future of LLM inference? Trends include long‑context support, retrieval‑augmented generation (RAG), mixture‑of‑experts scheduling, efficient reasoning, parameter‑efficient fine‑tuning, speculative and collaborative decoding, disaggregated and edge deployment, and energy‑aware inference.
Users demand longer context windows to handle documents, conversations and code bases; research explores ring attention, sliding window attention and extended Rotary Position Embedding (RoPE) techniques to scale context lengths. Block‑sparse attention and memory‑efficient context windows like RexB aim to support millions of tokens without linear memory growth. Combining FlashInfer with long‑context strategies will enable new applications like summarizing books or analyzing large code repositories.
RAG enhances model outputs by retrieving external documents or database entries; improved chunking strategies reduce context length and noise. GraphRAG builds graph‑structured representations of retrieved data, enabling reasoning over relationships and reducing token redundancy. Future inference engines will integrate retrieval pipelines, caching and knowledge graphs seamlessly.
MoE models will benefit from improved scheduling algorithms that balance expert load, compress gating networks and reduce communication. Research like MoEpic and MoEfic explores expert consolidation and load balancing to achieve dense‑model quality with lower compute. Inference engines will need to route tokens to the right experts dynamically, tying into routing strategies.
PEFT methods like LoRA and QLoRA continue to evolve; they enable on‑device fine‑tuning of LLMs using only low‑rank parameter updates. Edge devices equipped with AI accelerators (Qualcomm AI Engine, Apple Neural Engine) can perform inference and adaptation locally. This allows personalization and privacy while reducing latency.
The overthinking phenomenon occurs when models generate unnecessarily long chains of thought, wasting compute; research suggests efficient reasoning strategies such as early exit, reasoning‑output‑based pruning and input‑prompt optimization. Optimizing the reasoning path reduces inference time without compromising accuracy. Future architectures may incorporate dynamic reasoning modules that skip unnecessary steps.
Speculative decoding will continue to evolve; multi‑node systems like CoSine demonstrate collaborative drafting and verification with improved throughput. Developers will adopt similar strategies for distributed inference across data centers and edge devices.
Disaggregated inference separates compute and memory phases across heterogeneous hardware; combining with edge deployment will minimize latency by bringing decode closer to the user. Edge AI chips can perform decode locally while prefill runs in the cloud. This opens new use cases in mobile and IoT.
As AI adoption grows, energy consumption will rise; research is exploring energy‑proportional inference, carbon‑aware scheduling and hardware optimized for energy efficiency. Balancing performance with environmental impact will be a priority for future inference frameworks.
Clarifai stays on the cutting edge by integrating long‑context engines, RAG workflows, MoE routing and PEFT into its platform. Our upcoming inference suite will support speculative and collaborative decoding, disaggregated pipelines and energy‑aware scheduling. By partnering with Clarifai, you future‑proof your AI applications against rapid advances in LLM technology.
Optimizing LLM inference is a multifaceted challenge involving architecture, hardware, scheduling, model design and system‑level considerations. By understanding the distinction between prefill and decode and addressing memory‑bound bottlenecks, you can make more informed deployment decisions. Implementing batching strategies, multi‑GPU parallelization, attention and KV cache optimizations, and model‑level compression yields significant gains in throughput and cost efficiency. Advanced techniques like speculative and disaggregated inference, combined with intelligent scheduling and routing, push the boundaries of what’s possible.
Monitoring key metrics such as TTFT, TBT, throughput and percentile latency allows continuous improvement. Evaluating frameworks like vLLM, FlashInfer and TensorRT‑LLM helps you choose the right tool for your environment. Finally, staying attuned to emerging trends—long‑context support, RAG, MoE scheduling, efficient reasoning and energy awareness—ensures your infrastructure remains future‑proof.
Clarifai offers a comprehensive platform that embodies these best practices: dynamic batching, multi‑GPU support, caching, routing, streaming and metrics monitoring are built into our inference APIs. We integrate with cutting‑edge kernels and research innovations, enabling you to deploy state‑of‑the‑art models with minimal overhead. By partnering with Clarifai, you can focus on building transformative AI applications while we manage the complexity of inference optimization.

LLM inference is expensive because large models require significant memory to store weights and KV caches, and compute resources to process billions of parameters; decode phases are memory‑bound and sequential, limiting parallelism. Inefficient batching, routing and caching further amplify costs.
Static batching groups requests and processes them together but suffers from head‑of‑line blocking when some requests are longer than others; dynamic or in‑flight batching continuously adds and removes requests mid‑batch, improving GPU utilization and reducing tail latency.
Yes; techniques like quantization, distillation and parameter‑efficient fine‑tuning reduce model size and compute requirements, while disaggregated inference offloads heavy prefill stages to cloud GPUs and runs decode locally.
KV cache compression reduces memory usage by storing keys and values in lower precision or using block‑sparse formats; this allows longer context windows without scaling memory linearly. PagedAttention is an example technique that recycles cache blocks to minimize fragmentation.
Clarifai provides an inference platform that abstracts away complexity: dynamic batching, caching, routing, streaming, multi‑GPU support and advanced attention kernels are integrated by default. You can deploy custom models with quantization or MoE architectures and monitor performance using Clarifai’s analytics dashboard. Our upcoming features will include speculative decoding and disaggregated inference, keeping your applications at the forefront of AI technology.
Generative AI was supposed to supercharge productivity. Instead, many companies are grappling with something that researchers are calling “workslop,” or AI-generated output that looks polished but actually creates more work. Continue reading “How AI-Generated Content Is Destroying Team Productivity”
Modern AI applications increasingly rely on intelligent agents that do more than chat; they reason, search, and collaborate. By using Agno, a lightweight framework, and Clarifai’s GPT-OSS 120B, an open-source large language model accessible through an OpenAI-compatible API, you can create sophisticated agents with minimal setup.
This tutorial walks you through three progressively advanced examples:
A web-search agent that answers current events questions.
A knowledge-based agent that accesses domain-specific information.
A multi-agent system where specialized agents work together.
You will also find instructions for setting up your environment and a link to a Colab notebook with the full code so you can follow along.
To get started, install Agno along with libraries for search, PDF processing, vector storage, finance data, and the Clarifai SDK:
Make sure you have a Clarifai Personal Access Token (PAT) and set it as an environment variable so your agents can authenticate to access GPT-OSS-120B model from Clarifai.
The first example creates an agent that combines GPT-OSS 120B with DuckDuckGo search to answer questions about recent events. The language model interprets the query, the search tool fetches live information, and the agent then assembles a coherent response.
This straightforward setup demonstrates how easily you can combine reasoning with web search. It serves as the foundation for more complex agents.
Real-world applications often require access to proprietary or specialized data. In this example, you’ll build a Thai cuisine expert using a recipes PDF. The process includes:
Embedding the document with text-embedding-ada-002 from the Clarifai community.
Storing the vectors in LanceDB for efficient retrieval.
Configuring the agent to consult its knowledge base first, and only fall back to web search if necessary.
The agent returns a grounded recipe from the PDF and uses web search as a fallback. This approach is essential for building domain experts that rely on proprietary or internal data sources.
For complex scenarios, multi-agent orchestration can help divide and conquer tasks. Agno supports teams of agents, enabling specialization and collaboration. In this example:
A Web Research Agent fetches news and current information.
A Financial Analysis Agent pulls stock and market data.
A Coordinator synthesizes their outputs into a single response.
Here, each agent plays a distinct role, demonstrating how specialization leads to more comprehensive answers. This architecture is ideal for domains such as market research, technical analysis, or any multi-faceted problem that benefits from teamwork.
This walkthrough showcased how to build progressively more capable agents with Agno and GPT-OSS 120B:
Simple Web-Search Agent: A quick way to combine language understanding with live data.
Knowledge-Based Domain Expert: An agent that draws from proprietary data and uses web search only when needed.
Multi-Agent System: A coordinated approach where specialized agents collaborate to solve complex problems.
Each stage adds new capabilities, enabling you to build more advanced systems. For many use cases, a simple web-search agent may suffice. For specialized assistants or research tools, embedding your own data is crucial. And for multi-domain tasks, orchestrating multiple agents can be incredibly powerful.
There is no one-size-fits-all agent—each implementation can be fully customized based on your specific needs, business objectives, and domain requirements.
You can extend these patterns by building multi-agent teams, integrating domain-specific APIs, or experimenting with different agent designs such as coordinator-agent, collaborative-agent, or specialized-task agents. These approaches enable the creation of flexible, adaptive AI systems that can be tailored to solve complex, real-world challenges efficiently and effectively. To explore the examples in this tutorial, check out this notebook.
Agentic AI workflows are computationally demanding because they involve multiple agents interacting, reasoning over large contexts, and responding in real time. To operate effectively, these workloads require both high throughput and low latency.
The Clarifai Reasoning Engine provides the computational efficiency required for such workflows. Independent benchmarks by Artificial Analysis on the GPT-OSS-120B model show that it can process over 500 tokens per second with 0.3 seconds to first token, demonstrating the kind of performance that enables responsive and scalable multi-agent systems. You can try out the GPT-OSS-120B model.




![How to Protect Your Brand in an AI-Powered World with Jen Leonard [MAICON 2025 Speaker Series]](https://www.fazb.com.sa/wp-content/uploads/2025/10/How-to-Protect-Your-Brand-in-an-AI-Powered-World-with.png)
![How to Make AI Your Smartest Business Strategist with Jen Taylor [MAICON 2025 Speaker Series]](https://www.fazb.com.sa/wp-content/uploads/2025/10/How-to-Make-AI-Your-Smartest-Business-Strategist-with-Jen.png)

