
Orchestration has become a foundational concept in the digital era, allowing businesses to stitch together everything from container deployments to business processes into a seamless flow. When done well, orchestration transforms scattered tasks into cohesive, automated workflows, unlocking reliability, scalability and cost efficiency. In the AI space, Clarifai leads this orchestration revolution with its compute orchestration platform that works across clouds and on‑premises, helping organizations deploy and run AI efficiently. This article demystifies orchestration in computing, explains how it differs from automation, highlights major tools and use cases, and offers practical guidance for getting started.
Quick Digest: What’s Coming in This Guide
- What is orchestration? Orchestration coordinates multiple automated tasks and services to deliver an end‑to‑end outcome. It operates like a conductor managing an orchestra, ensuring every component plays its part at the right time.
- Why now? Companies rely on microservices, containers and hybrid clouds, making manual coordination impossible. Orchestration simplifies deployment, scaling and reliability.
- Key distinctions: Understand how orchestration differs from automation and choreography, and why these concepts matter.
- Types and tools: Explore different types of orchestration—containers, workflows, infrastructure—and compare leading tools like Kubernetes, Airflow, Terraform, and Clarifai’s orchestration platform.
- Benefits and challenges: Learn about the scalability, cost savings and reliability orchestration brings, as well as potential pitfalls like complexity and security risks.
- Best practices: Discover patterns such as decoupled design, observability, and CI/CD that ensure orchestration success.
- Emerging trends: Get a glimpse of the future with AI‑driven orchestration, edge computing, multi‑cloud strategies and generative AI that helps design systems.
- How to start: Follow a step‑by‑step guide and see how Clarifai’s compute orchestration and local runners can simplify your journey.
- FAQs: Wrap up with answers to common questions.
Understanding Orchestration—Definition, Evolution & Concepts
How Has Orchestration Evolved and What Does It Mean?
In computing, orchestration refers to the automated coordination of multiple tasks, services and resources to achieve a desired outcome. Think of a conductor guiding an orchestra—each musician (task) must play the right note at the right time for the piece (workflow) to come together. Similarly, orchestration tools manage dependencies, sequence tasks, handle failures and scale resources to deliver complex workflows. Initially, teams relied on cron jobs and custom scripts to automate single tasks. As systems grew into distributed architectures with containers and microservices, manual coordination became unsustainable. Modern orchestration emerged to bridge disparate components into unified workflows, making deployment and scaling seamless.
Why Is Orchestration Important in Today’s Digital Landscape?
Companies deploy applications across hybrid clouds, edge devices and on‑premises environments. Manual oversight can’t scale with such complexity. Orchestration solves this by managing lifecycles (start, stop, scale), handling retries, sequencing tasks, monitoring performance and recovering from failures automatically. In the AI domain, Clarifai’s unified control plane orchestrates AI models across different infrastructures, helping customers optimize costs and avoid vendor lock‑in. The modern emphasis on agility and DevOps makes orchestration critical—organizations can deploy changes faster while ensuring reliability.
Expert Insights & Statistics
- Survey data indicates that more than 80 % of organizations use containers in production, and 87 % run microservices, many managed by orchestration platforms.
- Dynatrace reports that organizations adopting container orchestration see improved scalability and more than 60 % of infrastructure workloads deployed on Kubernetes.
- Clarifai states that their compute orchestration can deliver up to 90 % less compute needed, handle 1.6 million inference requests per second, and provide 99.999 % reliability.
- Expert tip: Think of orchestration as the glue that binds microservices and tasks. Without it, your system is like a group of musicians practicing solo—talented individually but chaotic together.
Creative Example: The Factory Analogy
Imagine a factory assembling smartphones. Each station performs a specific task—cutting glass, installing chips, applying adhesive. If each station works independently, parts pile up or run out. An orchestration system acts like the factory supervisor: it determines when each station should start, stops when needed, handles shortages, and ensures every phone flows smoothly down the line. Similarly, orchestration in computing coordinates tasks so that data moves through pipelines, containers spin up and down, and services communicate reliably.
Orchestration vs. Automation vs. Choreography – Clear Distinctions
What’s the Difference Between Orchestration and Automation?
Automation involves executing a single task or a sequence of static steps automatically—like a script that backs up a database every night. Orchestration, on the other hand, coordinates multiple automated tasks, making decisions based on system state, dependencies and business rules. It ensures tasks run in the correct order, handle failures gracefully and scale up or down based on demand. Think of automation as playing one instrument and orchestration as leading an entire orchestra.
How Does Choreography Fit In?
Choreography relates primarily to event‑driven microservices. In choreography, each service listens for events and reacts independently without a central coordinator. This peer‑to‑peer model can be highly scalable but may introduce complexity if not designed carefully. Orchestration, in contrast, relies on a central controller (the orchestrator) that directs services and coordinates their interactions. Choosing between orchestration and choreography depends on your architecture: orchestration provides visibility and control; choreography offers loose coupling and autonomy.
Expert Insights & Advanced Tips
- Red Hat experts note that automation is a subset of orchestration; while automation can perform tasks, orchestration adds decision logic and state awareness.
- Microservice architects often blend both: they use orchestration for complex workflows that need oversight and choreography for event‑driven communication when services must respond quickly to changes.
- Advanced tip: Avoid coupling your orchestration tool tightly to business logic. Keep business rules separate so you can switch orchestrators without rewriting core services.

Types of Orchestration in Computing
Orchestration spans multiple domains. Understanding the different types helps you select the right tool for your workload.
Container Orchestration
Container orchestration automates the deployment, scaling and management of containerized applications. Kubernetes leads this space, supporting features such as auto‑scaling, service discovery, rolling updates and fault tolerance. Others include Docker Swarm (simpler but less flexible) and Apache Mesos (used for big data workloads). Clarifai’s compute orchestration integrates with Kubernetes but offers a unified control plane to manage AI workloads across multiple clusters and regions. The platform automatically provisions GPU or TPU resources, handles scaling, and optimizes compute usage.
Workflow or Data Orchestration
Workflow orchestration coordinates tasks across data pipelines, ETL/ELT processes and batch jobs. Tools like Apache Airflow, Dagster, Prefect and Argo Workflows allow you to define Directed Acyclic Graphs (DAGs) that specify task order, dependencies, scheduling and retries. These tools are crucial for data teams running complex pipelines. Clarifai’s orchestration platform enables deploying AI pipelines that include data ingestion, model inference and result post‑processing; you can run them on Clarifai’s shared compute, your VPC or on‑premises servers.
Microservices Orchestration
Microservices orchestration focuses on coordinating multiple services to deliver business processes. Service orchestrators or workflow engines manage API calls, handle retries and enforce business logic. Spring Cloud Data Flow and Camunda are examples, and serverless orchestrators like AWS Step Functions or Azure Durable Functions perform similar roles for event‑driven functions. Clarifai’s platform orchestrates AI microservices (e.g., image recognition, text analysis, custom models) to create complex AI pipelines.
Cloud & Infrastructure Orchestration
Infrastructure orchestration automates the provisioning, scaling and configuration of compute, storage and network resources. Tools like Terraform, AWS CloudFormation and Pulumi allow teams to define infrastructure as code (IaC), manage state and deploy across providers. Clarifai’s compute orchestration simplifies infrastructure management by offering a single control plane to run models on cloud, VPC or on‑premises, with auto‑scaling and cost optimisation.
Business Process Orchestration
Beyond IT, orchestration can coordinate enterprise workflows such as order fulfillment, supply chain management and HR processes. Business Process Management (BPM) platforms and BPMN modeling tools allow analysts to design workflows that cross departmental boundaries. They integrate with systems like ERP and CRM to automate tasks and approvals.
Edge & IoT Orchestration (Emerging)
With the rise of edge computing, orchestrating workloads across thousands of IoT devices becomes critical. Edge orchestration ensures that models run near the data source for low latency while central control manages updates and resource distribution. Research from MDPI highlights emerging frameworks for edge orchestration that use machine learning to predict workloads and schedule tasks. Clarifai’s compute orchestration supports deploying models to edge devices through Local Runners, which allow models to run locally while still being accessible via the Clarifai API.
Expert Insights & Data Points
- IDC predicts that by 2025, 75 % of enterprise data will be generated at the edge, requiring edge orchestration solutions.
- Clarifai’s Local Runners enable running models on workstations or on‑premises servers and exposing them through Clarifai’s API; this provides secure, low‑latency inference while using a unified management interface.
- Step Functions and Durable Functions simplify orchestrating serverless microservices. They handle retries, state machines and parallel execution, making them ideal for event‑driven architecture.

Leading Orchestration Tools & Platforms: Comparisons and Lists
Selecting the right orchestration tool depends on your workload, team skills and business goals. This section compares popular options across categories and highlights Clarifai’s unique strengths.
Container Orchestrators
|
Feature |
Kubernetes |
Docker Swarm |
Apache Mesos |
Clarifai Compute Orchestration |
|
Scalability & Ecosystem |
Industry standard with a vast ecosystem; runs microservices at scale. |
Simpler setup but limited features. |
Designed for large clusters; used by big data frameworks. |
Built on Kubernetes but provides unified control plane and AI‑optimized scaling. |
|
Ease of Use |
Steep learning curve; extensive configuration. |
Easier to start; fewer features. |
Complex; typically used in research environments. |
Abstraction layer hides Kubernetes complexity; automatically optimizes GPU/TPU usage. |
|
Managed Services |
EKS (AWS), GKE (Google), AKS (Azure). |
Docker Swarm is self‑managed. |
Mesos requires self‑hosting. |
Clarifai offers shared and dedicated compute, or connects to your own clusters. |
|
Use Cases |
General microservices, AI pipelines, hybrid cloud. |
Small teams wanting simple container management. |
Large‑scale data processing (Hadoop, Spark). |
AI/ML workloads, inference at scale, hybrid deployments, cost optimisation. |
Note: Clarifai’s platform is not a direct replacement for Kubernetes; it builds on top of it, focusing specifically on orchestrating AI models and inference pipelines. It provides a single control plane for managing compute across environments and adds features like GPU fractioning, batching, autoscaling and serverless provisioning.
Workflow & Data Orchestrators
- Apache Airflow: Popular open‑source DAG‑based orchestrator. Highly extensible and community‑supported but can be challenging to scale.
- Prefect: Modern Python‑based orchestrator with declarative flows and a cloud dashboard. Good for data engineering tasks.
- Dagster: A data‑centric orchestrator with strong type checking and observability features.
- Argo Workflows: Kubernetes‑native workflow engine, ideal for cloud‑native pipelines. Supports containerized tasks and artifacts.
Clarifai: Allows orchestrating AI workflows by chaining models (e.g., image detection → object classification → text extraction). The platform manages containerization and scaling automatically, so data scientists can focus on building workflows instead of infrastructure.
Infrastructure & IaC Orchestrators
- Terraform: Cloud‑agnostic tool for defining and provisioning infrastructure. Uses HCL language; state management can be complex.
- Pulumi: Allows writing IaC in languages like TypeScript, Python and Go; easier integration with existing codebases.
- Ansible: Agentless configuration management with a large module library; good for provisioning and deploying applications.
- CloudFormation: AWS‑native orchestration; integrates tightly with AWS resources.
Clarifai: Abstracts infrastructure details by offering a serverless compute layer for AI models. You can deploy models on Clarifai’s shared cloud, dedicated clusters or your own VPC/on‑premises environment, all through a consistent API.
Serverless & Function Orchestrators
- AWS Step Functions and Azure Durable Functions: Provide state machines for orchestrating serverless functions, handling retries, branching and parallelism.
- Google Workflows: Similar to Step Functions but integrated with Google Cloud services.
These services are well‑suited for event‑driven microservices and IoT applications. Clarifai can integrate serverless functions within AI pipelines; for example, a Step Function could trigger Clarifai’s inference API.
Expert Insights & Key Statistics
- DZone reports that 54 % of Kubernetes users adopt it for hybrid/multi‑cloud deployments, 49 % for new cloud‑native apps and 46 % for modernizing existing apps. This shows the versatility of container orchestration.
- Survey results reveal that 75 % of developers use Kubernetes and 87 % run microservices on it. However, only 54 % of projects are mostly successful, indicating room for improvement.
- Clarifai’s compute orchestration helps reduce compute costs by fractioning GPUs, batching requests and using spot instances; this can cut expenses by up to 90 %.
- Fairwinds predicts that cluster consolidation, multi‑cloud strategies and tools like Karpenter will dominate orchestration by 2025.
Benefits & Use Cases of Orchestration
How Does Orchestration Deliver Value?
Scalability & Elasticity
Orchestration automatically scales services based on demand, spinning up additional instances during peak times and scaling down when idle. In container orchestrators like Kubernetes, autoscalers monitor CPU/memory and adjust the number of pods. In Clarifai’s platform, autoscaling works across clusters and regions, handling millions of inference requests per second while minimizing resource use.
Reliability & Fault Tolerance
Orchestrators provide self‑healing capabilities—if a container or service fails, the orchestrator restarts it or reroutes traffic. They manage rolling updates, handle retries and ensure overall system stability. Clarifai’s orchestration offers 99.999 % reliability, ensuring AI services stay available even during infrastructure failures.
Faster Deployment & Time to Market
CI/CD pipelines integrated with orchestration allow developers to push code frequently with confidence. Rolling updates, blue‑green deployments and canary releases ensure zero downtime. By automating deployment tasks, teams can iterate faster.
Cost Optimization & Resource Efficiency
Orchestrators allocate resources efficiently, preventing overprovisioning. Clarifai uses GPU fractioning, batching, autoscaling and spot instances to optimize costs. This means models only use GPU time when needed, significantly reducing expenses.
Multi‑Cloud & Hybrid Operations
Orchestration allows deploying workloads across multiple clouds, on‑premises data centers and edge nodes. This flexibility avoids vendor lock‑in and enables global scalability. Clarifai’s control plane can manage models across your VPC, on‑premises servers and Clarifai’s cloud.
AI/ML & Edge Use Cases
With the growing adoption of AI and IoT, orchestrating models at scale becomes critical. Clarifai’s platform lets you run models at the edge via Local Runners while maintaining central control and monitoring. This ensures low‑latency inference for applications like autonomous vehicles, retail cameras and industrial sensors.
Business Process Automation
Beyond IT, orchestration automates cross‑departmental workflows. For example, an order processing pipeline might orchestrate inventory checks, payment processing and shipping notifications, integrating with ERP and CRM systems.
Expert Insights & Data Points
- Survey data shows that the microservices orchestration market is projected to reach USD 13.2 billion by 2034 with a 21.2 % CAGR.
- Dynatrace reports that 63 % of organizations deploy Kubernetes for infrastructure workloads.
- Industry opinion: Orchestration doesn’t just save money—it enhances innovation by freeing engineers from operational toil. This shift empowers teams to focus on building value.

Challenges, Risks & When Not to Use Orchestration
Where Does Orchestration Fall Short?
Complexity & Learning Curve
While orchestration simplifies operations, platforms like Kubernetes come with a steep learning curve. Managing clusters, writing YAML manifests and configuring RBAC can be overwhelming for small teams. Developers report that Kubernetes setup and management are resource‑intensive.
Security Risks & Misconfiguration
Misconfigured orchestration can open security holes. Without proper RBAC, network policies and vulnerability scanning, clusters become susceptible to attacks. Survey data reveals that 13 % of developers think orchestration worsens security. Tools like Clarifai include best‑practice security defaults and allow deployment into your own VPC or on‑premises environment without exposing ports.
Cost Overrun & Resource Sprawl
If not monitored, orchestration can lead to wasted resources. Idle pods, over‑provisioned nodes and persistent volumes drive up cloud bills. According to Fairwinds research, 25 % of developers find cost optimization challenging. Clarifai mitigates this by automatically adjusting compute to workload demand.
Latency & Performance Overhead
Adding orchestration layers can introduce latency. Tools need to manage scheduling and context switching. For latency‑sensitive edge applications, over‑orchestration might not be ideal.
Over‑Engineering for Small Projects
For simple monolithic applications, orchestration may be overkill. Microservices and orchestration bring many benefits, but they also introduce complexity. Reports show that not all microservice projects succeed, with only 54 % mostly successful. Evaluate whether your project truly benefits from microservices or if a simpler architecture would suffice.
Vendor Lock‑In
Choosing a proprietary orchestrator can lock you into a single provider. Look for tools supporting open standards. Clarifai addresses this by allowing customers to connect their own compute resources and avoid cloud vendor lock‑in.
Expert Insights & Cautionary Tales
- Fairwinds survey reveals that the top challenges developers face with Kubernetes include high complexity, cost optimization and security.
- O’Reilly’s microservices study reports that while many companies adopt microservices, only half find substantial success, underscoring the need for planning and expertise.
- Advice: Start small. Use managed services or platforms like Clarifai to minimize complexity. Optimize gradually and avoid blindly splitting monoliths.
Best Practices & Architectural Patterns for Orchestration
How to Design Effective Orchestration Architectures
Design for Decoupling & Statelessness
Orchestration works best when services are loosely coupled and stateless. Each service should expose clear APIs and avoid storing state locally. This enables the orchestrator to scale services horizontally without coordination headaches. Use patterns like the Strangler Fig to gradually break monoliths into microservices.
Balance Orchestration & Choreography
Not every interaction needs central orchestration. Use event‑driven architecture where services can react to events independently (choreography) and apply orchestration for complex workflows requiring control. For example, use Step Functions to orchestrate a data pipeline but rely on asynchronous messaging (Kafka) for simple event flows.
Adopt CI/CD & Infrastructure as Code (IaC)
Automate everything: use CI/CD to deploy application code and IaC tools (Terraform, Pulumi) to manage infrastructure. This ensures reproducibility, easier rollbacks and fewer manual errors.
Implement Observability & Monitoring Early
Instrumentation is critical. Deploy metrics, logs and traces to understand performance. According to surveys, 65 % of organizations use Grafana, 62 % use Prometheus and 21 % use Datadog for observability. Clarifai’s platform provides monitoring and cost dashboards, allowing you to track inference usage and performance.
Automate Security & Apply Least Privilege
Enable RBAC, enforce network policies and integrate vulnerability scanning into CI/CD. Tools like OPA (Open Policy Agent) or Kyverno can enforce policies. Clarifai’s compute orchestration allows you to deploy models into your own VPC or on‑premises clusters, controlling ingress and egress ports.
Optimize Costs & Autoscaling
Set resource requests and limits appropriately, use autoscaling policies, and leverage spot instances or pre‑emptible VMs. Clarifai automatically scales compute and uses GPU fractioning and batching to minimize costs.
Document Workflows & Version Control
Use BPMN diagrams or YAML manifests to document workflows. Track changes through version control. This ensures reproducibility and collaboration.
Expert Insights & Research Highlights
- Researchers apply long short‑term memory (LSTM) networks to predict workloads and inform autoscaling decisions in microservices.
- Generative AI and large language models (LLMs) are being used to suggest microservice boundaries and optimize orchestration patterns.
- Fairwinds predicts the rise of cluster consolidation and multi‑cloud orchestration tools like Karpenter.
- Clarifai automatically handles model containerization and packing, so you focus on building models rather than managing Dockerfiles.
Case Studies & Real‑World Examples
Success Stories of Orchestration
Netflix: Microservices at Scale
Netflix famously migrated from a monolithic architecture to over 700 microservices to support its global streaming service. Kubernetes (via Titus) orchestrates containers to handle millions of concurrent streams, performing rolling updates and autoscaling effortlessly. This transformation enabled Netflix to scale globally, experiment quickly and deliver a high‑quality user experience. While Netflix built its own orchestration, many companies can replicate similar benefits by adopting tools like Kubernetes or Clarifai’s compute orchestration for AI workloads.
Uber: Rapid Feature Integration
Uber transitioned to microservices to reduce feature integration time from three days to three hours. They reorganized 2,200 services into 70 domains, creating a domain‑driven architecture that improved operational efficiency. Orchestration played a key role in coordinating these services and ensuring reliability under heavy load.
Banking & Finance
Financial institutions deploy microservices for transaction processing and risk analysis. Orchestration ensures compliance and auditability. AI models for fraud detection run in orchestrated pipelines, requiring high reliability and low latency.
Retail & E‑Commerce
E‑commerce platforms use orchestration to manage inventory, payments, recommendations and delivery logistics. AI models for image search, product tagging and customer personalization run through orchestrated workflows. Clarifai’s platform can orchestrate these models across cloud and on‑premises, optimizing cost and latency.
Cautionary Tales
- A startup attempted to adopt microservices too early. The overhead of managing Kubernetes and service communication slowed development, leading to missed deadlines. Eventually, they returned to a monolithic service until their team matured.
- A research organization ran a data pipeline with numerous dependencies but lacked orchestration. When one task failed, the entire pipeline broke. After adopting a workflow orchestrator (Airflow), they gained visibility into failures and improved reliability.
Expert Insights & Lessons Learned
- Enterprises need to evaluate readiness before diving into microservices. If team size is small and the domain is stable, a monolith may suffice.
- Case studies show that success hinges on careful planning, adoption of observability and robust deployment strategies. Merely adopting microservices without culture change leads to failure.
Emerging Trends & Future of Orchestration (2025+ Outlook)
What Innovations Are Shaping Orchestration’s Future?
AI‑Driven & Predictive Orchestration
Machine learning techniques like LSTM and Bi‑LSTM can analyze metrics and predict workloads, enabling orchestrators to scale ahead of demand. Tools such as Karpenter (AWS) and Cluster Autoscaler use predictive algorithms to manage node pools. Clarifai leverages AI to optimize inference workloads, batching requests and scaling clusters efficiently.
Edge & IoT Orchestration
As IoT devices proliferate, orchestrating workloads at the edge becomes crucial. 5G and AI chips enable real‑time processing on devices. Orchestrators must manage remote updates, handle intermittent connectivity and ensure security. Local Runners from Clarifai demonstrate how to run models at the edge while maintaining centralized control.
Multi‑Cloud & Hybrid Orchestration
Organizations increasingly spread workloads across multiple clouds to avoid vendor lock‑in and increase resilience. Tools like Crossplane and Rafay manage multi‑cluster deployments. Clarifai’s orchestration supports multi‑cloud by enabling models to run on Clarifai’s cloud, dedicated clusters or customer VPCs.
Serverless & Function Orchestration
Serverless architectures reduce operational overhead and cost. Future orchestrators will blend container and function orchestration, enabling developers to choose the best compute paradigm for each task.
Generative AI & LLM‑Assisted Design
Generative AI can analyze code and traffic patterns to suggest microservice boundaries, security policies and resource allocation. Imagine an orchestrator that recommends splitting a service into two based on usage or suggests adding a circuit breaker pattern. Clarifai’s AI expertise positions it well to integrate such features into its platform.
Observability & FinOps Evolution
Observability tools will use AI to detect anomalies, foresee capacity bottlenecks and recommend cost savings. FinOps practices will become integral, with orchestrators providing cost dashboards and optimization hints. Clarifai’s cost monitoring helps users track compute spending and efficiency.
Security & Compliance
With increasing threats, zero‑trust architectures, policy‑as‑code and supply chain security will be standard. Orchestrators will integrate scanning and policy engines into the workflow.
Expert Insights & Research Trends
- Market analysts forecast significant growth for AI‑driven orchestration and edge computing solutions.
- Fairwinds notes that cluster consolidation and multi‑cloud strategies will drive orchestration adoption.
- MDPI review highlights research into AI methods for optimizing microservices design and orchestration.

Getting Started with Orchestration—Skills, Steps & Resources
What Skills Are Required?
- Fundamental knowledge of distributed systems: Understand concurrency, networking, service discovery and fault tolerance.
- Containerization basics: Learn Docker and how to build container images.
- Programming languages & APIs: Proficiency in languages like Python, Go or Java; familiarity with REST APIs.
- Infrastructure & Networking: Learn about VPCs, subnets, load balancers and DNS.
- CI/CD & IaC: Experience with pipelines (Jenkins, GitHub Actions) and IaC tools.
- Security concepts: Understand RBAC, TLS, secrets management and policy enforcement.
Step‑by‑Step Guide to Implementing Orchestration
- Set Up Docker: Install Docker and run a simple container (e.g., Nginx). Create your own container image for a small app.
- Deploy to Kubernetes (or Clarifai):
- Install a local Kubernetes cluster (e.g., minikube) or use a managed service (EKS, GKE).
- Write a deployment manifest for your container and deploy it. Observe how pods scale and restart.
- Alternatively, sign up for Clarifai’s platform, upload a model, and run it on shared compute. Clarifai handles containerization and scaling for you.
- Define a Workflow: Use Airflow or Dagster to build a simple DAG (e.g., ETL pipeline). Configure dependencies and schedules.
- Add Observability: Integrate Prometheus and Grafana or use Clarifai’s built‑in monitoring to track metrics.
- Secure & Optimize: Apply RBAC, secrets management and resource limits. Experiment with autoscaling parameters.
- Scale to Production: Evaluate multi‑cloud deployment, high availability and backup strategies. Consider using Clarifai for AI workloads to reduce operational burden and access features like GPU fractioning.
Tips for Small Teams
- Use managed services: For container orchestration, choose a managed Kubernetes (GKE, EKS, AKS) or a specialized AI platform like Clarifai. This reduces operational overhead.
- Start simple: Begin with a monolith and gradually break off services. Introduce orchestration only where needed.
- Invest in training: Encourage team members to take Kubernetes and cloud certifications (CKA, CKAD). Clarifai offers documentation and tutorials tailored to AI deployment.
- Join communities: Engage with open‑source communities (CNCF, Kubernetes Slack) and attend webinars to stay updated.
Clarifai Product Integration – Compute Orchestration & Local Runners
Clarifai offers a compute orchestration platform designed specifically for AI/ML workloads. Here’s how it integrates naturally into your orchestration journey:
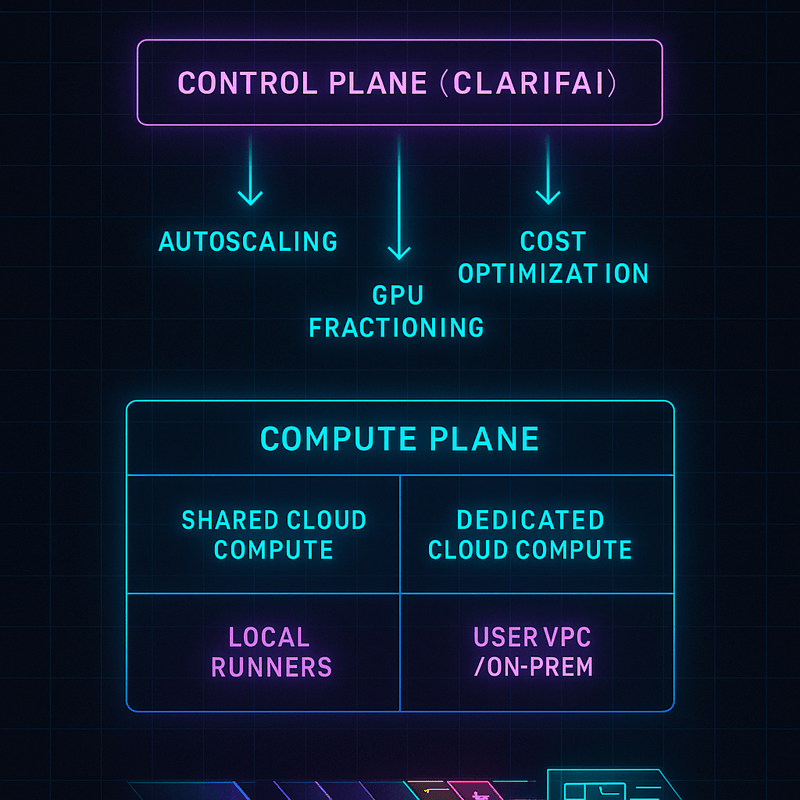
- Unified Control Plane: Manage your AI compute, costs and performance through a single portal. This control plane abstracts underlying Kubernetes complexity and lets you run models on shared or dedicated hardware.
- Flexible Deployment Options: Deploy models on Clarifai’s cloud, your VPC, or on‑premises clusters. Options include shared SaaS, dedicated SaaS, self‑managed VPC, on‑premises, multi‑site, and full platform deployment.
- Cost Optimization Features: Clarifai leverages GPU fractioning, batching, autoscaling, and spot instances to reduce compute costs.
- Local Runners: Run models locally on workstations or servers and expose them via Clarifai’s API. This allows low‑latency inference without sending data to the cloud.
- Model Management & Packaging: Clarifai handles containerization, model packing and dependency management, so you can focus on building models.
- Monitoring & Analytics: The platform provides dashboards to monitor inference requests, compute usage and costs, ensuring transparency.
- Enterprise-Grade Security: Deploy models into your own VPC or on‑premises clusters without exposing ports; Clarifai adheres to security best practices.
By incorporating Clarifai into your orchestration strategy, you gain the benefits of Kubernetes and other orchestrators while leveraging specialized AI optimization and cost control.

Frequently Asked Questions
Q1: What is the difference between orchestration and automation?
A: Automation executes repetitive tasks automatically (e.g., backing up a database), whereas orchestration coordinates multiple automated tasks, making decisions based on dependencies and system state. Orchestration involves scheduling, scaling, error handling and complex workflows.
Q2: Do I always need orchestration for microservices?
A: Not necessarily. Small microservice systems can use event‑driven communication without central orchestration. As complexity grows—hundreds of services, multi‑cloud deployments, compliance requirements—an orchestrator becomes essential for reliability and visibility.
Q3: How does Clarifai’s orchestration differ from Kubernetes?
A: Clarifai builds on Kubernetes to provide a unified control plane for AI workloads. It hides Kubernetes complexity, automatically handles containerization and scaling, and optimizes GPU/TPU usage. It also offers specialized features like Local Runners and AI cost dashboards.
Q4: Can I use Clarifai’s local runners without internet access?
A: Yes. Local Runners let you run models on local machines or private clusters and expose them via Clarifai’s API. They operate offline and sync results when connectivity is restored.
Q5: Which orchestrator should I choose for data pipelines?
A: For data pipelines, consider Airflow, Dagster, Argo Workflows or Prefect. If your pipelines involve AI/ML models, Clarifai can orchestrate model inference alongside data processing, providing cost optimization and multi‑cloud deployment.
Q6: What are the upcoming trends in orchestration?
A: Expect AI‑driven scaling, edge & IoT orchestration, multi‑cloud strategies, serverless function orchestration, generative AI assisting design, FinOps integration, and enhanced security.
Conclusion: Orchestrating the Future
Orchestration is more than just a buzzword—it’s the backbone of modern computing, enabling organizations to deliver reliable, scalable and cost‑effective services. By automating coordination across containers, microservices, workflows and infrastructure, orchestration unlocks agility and innovation. However, it also demands careful planning, security and observability. Platforms like Clarifai’s compute orchestration combine best‑in‑class orchestration with AI‑specific optimizations, making it easier for businesses to deploy and run AI workloads anywhere. As the future brings AI‑driven orchestration, edge computing and generative design, embracing orchestration today ensures your systems are ready for tomorrow’s challenges.






%20%20(2).png?width=1000&height=629&name=Output%20Speed%20vs%20Price%20(10%20Sep%2025)%20%20(2).png)
%20%20(1).png?width=1000&height=657&name=Latency%20vs%20Output%20Speed%20(10%20Sep%2025)%20%20(1).png)










 Quantization for LLMs and VLMs: State‑of‑the‑Art Innovations
Quantization for LLMs and VLMs: State‑of‑the‑Art Innovations
 Tools and Libraries for Quantization: From Open‑Source to Clarifai’s Platform
Tools and Libraries for Quantization: From Open‑Source to Clarifai’s Platform