Quick Summary: Why is data orchestration so important in 2025?
Data orchestration brings together different operations like data extraction, transformation, storage, and AI inference into one process. This makes sure that everything is consistent, scalable, and compliant. It’s not just about scheduling; it’s what holds cloud resources and services together across environments.
What Is Data Orchestration?
Data orchestration is the coordinated administration and automation of data pipelines and services across cloud and on-prem systems. Orchestration is different from simple automation since it puts together all the processes into end-to-end, policy-driven workflows. A data orchestrator makes ensuring that actions run in the right order, whether they be batch ETL jobs, streaming processes, or AI inference calls. It also manages dependencies and resolves failures. For instance, a pipeline might automatically get data from IoT sensors, change it, run a Clarifai model to recognize images, and put the findings onto a dashboard.
Data orchestration is different from ETL since it doesn’t care about the underlying computing or storage. It can coordinate numerous ETL activities, machine learning pipelines, real-time analytics, or container operations. This kind of adaptability is very important for modern AI tasks that use structured data, computer vision, and natural language processing.
Why It’s Important in 2025
Orchestrators are very important now since there is so much data and it needs to be analyzed in real time. By 2025, 75% of business data will be created and processed at edgemontecarlodata.com, which means that centralized batch processing won’t work anymore. Companies can find 60 to 75 percent of their underutilized data through orchestration and better pipelinesresearch.aimultiple.com, which shows how useful it is. Orchestration also cuts down on mistakes made by people and speeds up deployment cyclesdatacamp.com, making sure that operations are always the same and reliable in complicated settings.
Expert Advice
- Marcin Najder says that “the future of data engineering is event-driven and orchestrated.” He stresses that pipelines must be able to adapt to events and grow as needed.
- Andrew Ng is a big supporter of data-centric AI. He wants teams to spend more time refining data pipelines than changing models, which is what orchestration is all about.
- Clarifai engineers say that combining compute orchestration and model inference cuts down on latency and makes MLOps operations easier, which lets AI models be deployed quickly and on a large scale.
- According to industry experts, orchestration solutions not only make workflows easier, but they also ensure compliance by enforcing rules and keeping track of every step.
Example:
Think about a smart city concept with thousands of cameras. Data orchestrators gather video streams, utilize Clarifai’s image recognition API to find traffic accidents, and send out alerts right away. If there were no orchestration, developers would have to write scripts for each step by hand, which would take longer and give different outcomes.

How Do You Pick a Data Orchestration Tool?
In short, what things should you think about while picking a tool?
When choosing the correct orchestrator, you need to think about how scalable, easy to use, easy to integrate, provide real-time support, cost, security, and vendor reliability, and make sure it fits with your team’s skills and workload.
Important Things to Look at
- Performance and Scalability
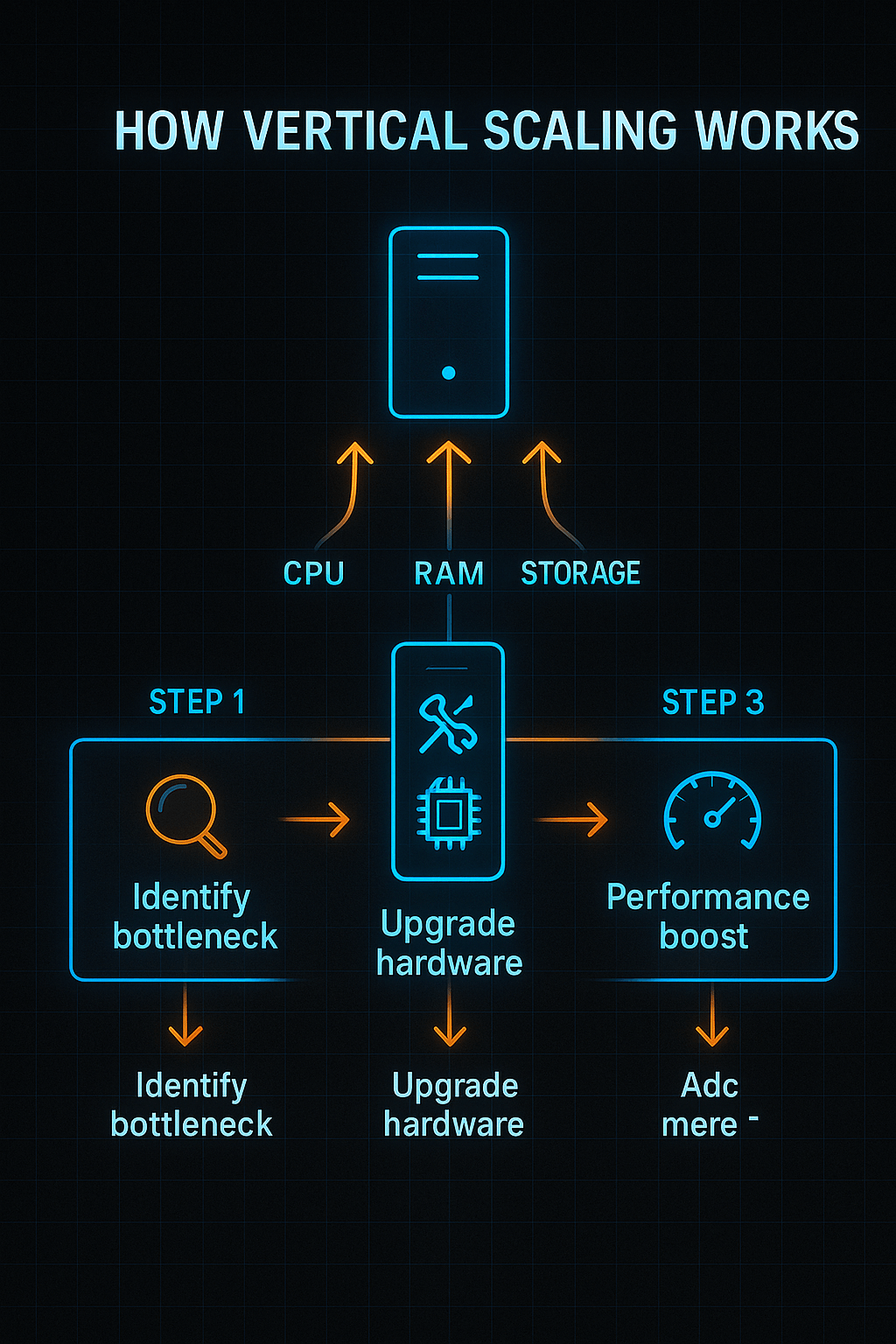
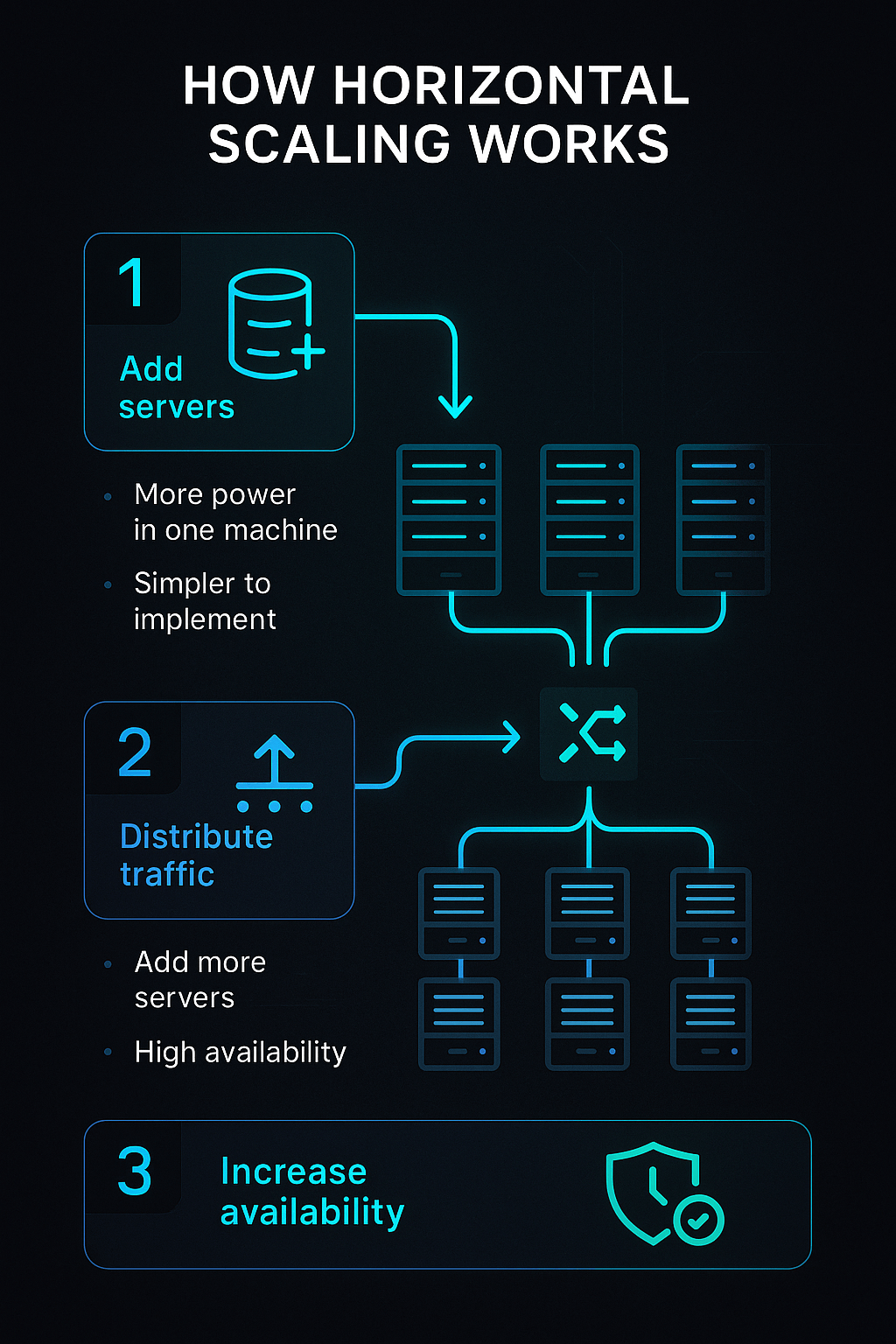
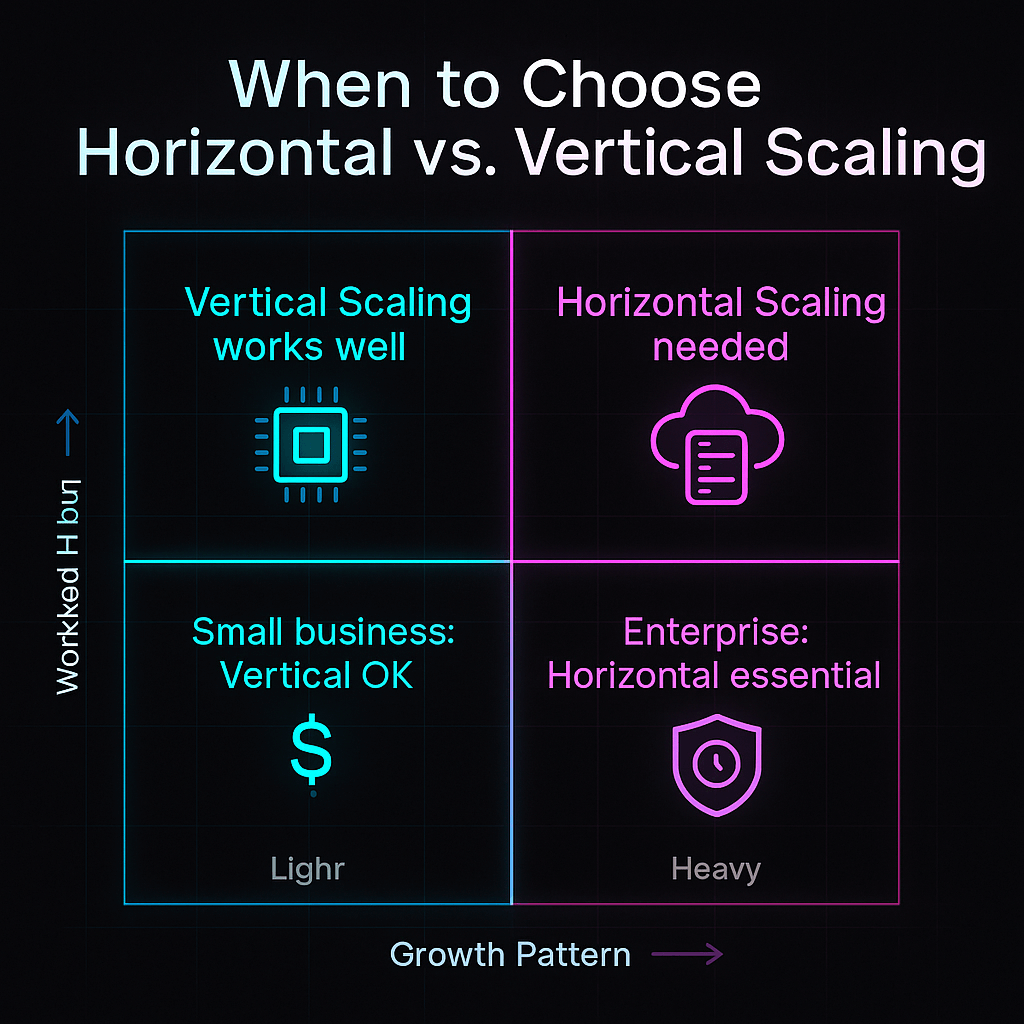
A good orchestrator must be able to handle more data and workloads at the same time without slowing down. Batch tasks, streaming pipelines, and ML workflows should be able to grow both horizontally and vertically. Clarifai’s compute orchestrator and other tools operate on Kubernetes and use autoscaling for workloads that require a lot of AI.
- How Easy It Is to Use and How Developers Feel About It
Some tools are code-first, like Python DAGs, while others provide low-code or no-code interfaces with workflow designers that let you drag and drop. Pick what works best for your team: data engineers could like coding better, while analysts might like visual builders more. Clarifai’s platform has an easy-to-use UI and API access, which lets users of all ability levels orchestrate models.
- Connecting and Integrating
Check out the supported connectors for databases, message queues, APIs, storage systems, and AI services. An orchestrator should be able to easily work with Clarifai for model inference and with Snowflake, BigQuery, Apache Kafka, and Kubernetes. For flexibilityestuary.dev, plugin ecosystems or support for bespoke operators are a must.
- Real-Time and Event-Driven Features
As edge computing and streaming datamontecarlodata.com become more popular, orchestrators need to be able to handle event-driven triggers, streaming ETL, and execution with low latency. Look for things like sensors or hooks that respond to file arrivals, Kafka messages, or API calls.
- Price and Licensing
You can use open-source technologies for free, but you have to host and maintain them yourself. Enterprise platforms offer help, but they usually charge based on how many people use them or how much they cost. Think about the overall cost of ownership, which includes training, infrastructure, and the possibility of being locked in with a vendor.
- Safety and Compliance
Data governance is a must—make sure your technologies support encryption, role-based access, audit logging, and following the rules set by GDPR and other laws. Clarifai’s platform offers RBAC, secure inference endpoints, and deployment on-premises for applications that need extra security.
- Support from the Vendor and the Community
Think about how easy it is to get help, read documentation, get training, and join a lively community. A strong open-source community shares plugins and best practices, while enterprise suppliers offer SLAs and specialized support.
Expert Advice
- Ben Lorica says that you should test orchestrators by running a proof of concept that mirrors your real workload. Synthetic benchmarks sometimes don’t show how well something works in the real world.
- Clarifai’s CTO said that AI model inference should be a top priority for orchestrators in the AI era. This will make it easier for data and ML teams to work together.
- Analysts say that multi-cloud orchestration adds problems such different APIs and pricingdatacamp.com. To avoid these problems, platforms should be agnostic and have strong abstractions.
Example
Imagine a marketing team that wants to set up a daily sentiment analysis pipeline. They need to get tweets, break them down, use Clarifai’s text analysis model to classify the sentiment, and then send the results to a dashboard. Choosing a platform that has built-in API connectors and a simple scheduling UI lets people who aren’t tech-savvy run this process.

What Are the Best Open-Source Data Orchestration Platforms in 2025?
In short, what open-source tools should you be aware of?
Apache Airflow is still the most popular open-source orchestrator, but new ones like Dagster, Prefect, Kestra, Flyte, and Mage have unique capabilities like type-checked pipelines and declarative workflows that provide teams more options.
The Standard That Has Been Around for a While: Apache Airflow
Airbnb built Apache Airflow, which rapidly became the open-source platform for creating, scheduling, and monitoring data workflowsestuary.dev. Airflow employs Python code to define DAGs, which gives engineers complete control over how tasks work. It has a built-in scheduling system, retry logic, a lot of plugins, and a web UI for watching and fixing pipelines at pipelinesestuary.dev. Airflow is flexible since its ecosystem is open to new operators for Snowflake, Databricks, Spark, and Clarifai’s API.
- Pros: a big community, configurable Python DAGs, a lot of connectors, and good scheduling.
- Disadvantages: Setting up and scaling might be hard; the web UI may seem old; there is no native type system.
Dagster: Aware of Types and Driven by Assets
Dagster adds asset-oriented orchestration and type-checked pipelines, which make sure that the data is valid at every step. It can handle a lot of metadata, split pipelines, and schedule events based on when they happen. Dagster’s “Software-Defined Assets” method treats data outputs like first-class citizens, which makes it possible to trace lineage and versions.
- Pros: Good experience for developers, type safety, asset lineage, and built-in testing.
- Disadvantages: The community is smaller than Airflow’s, the features are still being worked on, and you need to know Python.
Prefect: Hybrid Execution and Cloud Management
With hybrid execution, flows can operate locally, on Kubernetes, or through Prefect Cloud. The Prefect Cloud UI lets you monitor tasks, try them again, and set up schedules. The Python API is easy to use. The latest version of Prefect, 2.0, has low-code features and better concurrency.
- Pros: Can be deployed in several ways, has a solid UI, is easy to use, and can handle errors.
- Disadvantages: You need a license for Prefect Cloud, and the community is smaller than Airflow’s.
Kestra: Serverless and Declarative Orchestration
Kestra uses YAML to describe processes, which is a way of thinking about Everything as Code. It lets you use complicated branching, dynamic tasks, and event triggers. Kestra is great for streaming data because it is built on top of Pulsar and Kafka. It also scales like a serverless service.
Flyte: Managing ML Workflows
Flyte is all about machine learning and data science pipelines. It has great support for containers, Kubernetes, and versioning. It keeps track of lineage and artifacts, which makes it perfect for MLOps.
Mage and Argo: New Players on the Scene
Mage offers a no-code interface and Python notebooks for making pipelines, which helps analysts and data developers work together. Many ML platforms employ Argo Workflows, which runs on Kubernetes and works with Kubeflow.
Picking from Open-Source Choices
Choose Airflow since it is widely used and has many plugins. Pick Dagster or Prefect if you need superior type safety or hybrid execution. Choose Kestra for streaming compatibility and declarative processes. Mage and Argo are good for low-code or Kubernetes-native needs, whereas Flyte is good for ML pipelines.
Expert Advice
- According to Ry Walker, the founder of Airflow, the company’s future depends on making advances in little steps and connecting with data lineage, not on coming up with new ideas.
- Nick Schrock, the founder of Dagster, says that data should be treated like assets with lineage and versioning. This makes pipelines less likely to have issues.
- Chris White, the CEO of Prefect, supports “negative engineering,” which means that orchestrators take care of faults and retries so that engineers may focus on the fundamental logic.
- The data platform team at Clarifai recommends using Airflow operators to call Clarifai models, which will make sure that inference is the same across all pipelines.
Example
Think of a research center that looks at satellite photographs. They use Apache Airflow to manage the workflow: they download the images, run Clarifai’s vision model to find deforestation, store the results in a geographic database, and send alerts to environmental agencies. Dagster could add type safety, which would make sure that the input photos have the right resolution before inference.
Which Enterprise Data Orchestration Platforms Should You Look Into?
Quick Summary: Which business tools are the best?
Enterprise systems like ActiveBatch, RunMyJobs, Stonebranch, and Clarifai’s compute orchestrator offer drag-and-drop interfaces, SLA guarantees, and advanced integrations. These features make them desirable to businesses that need help and the opportunity to grow.
ActiveBatch: A Workflow Designer with Few Lines of Code
ActiveBatch blends workload automation and data orchestration to assist ETL procedures in both on-premises and cloud environments. It comes with connectors that are already made for Informatica, SAP, IBM DataStage, Hadoop, and other programs. Its drag-and-drop interface lets people who aren’t developers construct complicated workflows, and sophisticated users can write scripts in PowerShell or Python.
- Pros: UI with low code, a lot of connectors, SLA monitoring, and connectivity with old systems.
- Cons: It might be hard to install and take a lot of resources; licensing fees can be costly.
Redwood’s RunMyJobs: SaaS Orchestration
RunMyJobs is a SaaS application that makes IT work easier by managing data transfers between several platforms. It has interfaces to SAP Datasphere, Databricks, Oracle Fusion, and OpenVMS, as well as load balancing and lightweight agents. It is a cloud service, therefore it doesn’t need as much installation and maintenance on site.
- Pros: SaaS architecture, robust connectors, dependable uptime, and compliance with ITIL and ISO 20000.
- Cons: Users say that adjusting for daylight saving time and keeping track of paperwork is hard.
Stonebranch UAC: Managed File Transfer and Centralized Control
The Universal Automation Center (UAC) from Stonebranch is a single console that lets you control data pipelines in hybrid systems. It has a workflow builder that lets you drag and drop files, built-in controlled file transfer with encryption, and ready-to-use integrations for Hadoop, Snowflake, and Kubernetesresearch.aimultiple.com. UAC is good for DataOps teams since it allows pipelines-as-code and version control.
Fortra’s JAMS and Other Platforms
Fortra’s JAMS Scheduler has scripted and parameter-driven workflows that are great for teams that are familiar with code. Rivery and Keboola offer cloud-native ETL and orchestration with easy-to-use interfaces and charging depending on usage. Azure Data Factory and Google Cloud Dataflow are both focused on integrating and processing data within their own ecosystems. They both enable visual pipeline architecture and the potential to grow.
Orchestration of Clarifai Compute
Clarifai has a compute orchestration layer that is made for AI workflows. This lets developers install, scale, and manage AI models and inference pipelines along with other data chores. It works with Clarifai’s API, local runners, and edge deployment options to make sure that models execute successfully in orchestrated workflows. Clarifai’s solution has built-in monitoring and auto-scaling, which lowers latency and makes MLOps easier.
Picking an Enterprise Platform
Businesses should think about how well the vendor supports them, how many features they offer, and how hard it is to integrate them. ActiveBatch is great for integrating businesses; RunMyJobs is good for businesses that want a managed service; Stonebranch is good for transferring files; and Clarifai is good for AI model orchestration.
Expert Advice
- Gene Kim says to choose an orchestrator that is open to APIs so that it can work with your current DevOps toolchains and monitoring systems.
- According to Clarifai’s solution architects, putting model inference inside workflows cuts down on context shifts and makes sure that outcomes are always the same throughout data pipelines.
- Enterprise IT leaders stress the need of looking at vendor roadmaps and community comments to avoid being locked in and to keep innovation going.
Example
A bank that operates in many countries does nightly batch jobs and detects fraud in real time. They employ ActiveBatch for the main ETL activities, RunMyJobs for cloud-based jobs, and Clarifai’s compute orchestration to deploy anti-fraud models that look at transaction streams as they happen.

How Do You Set Up Real-Time and Streaming Data Pipelines?
Why Do Streaming Workflows Need Orchestration? Here’s a Quick Summary.
Real-time analytics and streaming data need orchestration that can respond to events, handle continuous flows, and keep latency low. Streaming workloads get brittle and hard to scale if they aren’t properly orchestrated.
The Growth of Streaming Data
The desire for quick information has reached a breaking point; batch reporting can’t meet the needs of the market today. Real-time processing is needed for the constant streams that come from IoT devices, 5G networks, and event-driven business models. Edge computing brings analytics closer to the source of the data, which cuts down on latency and bandwidth use.
Orchestration and Streaming Technologies
Kafka from Apache
Apache Kafka is a distributed streaming platform that lets you develop real-time pipelines and apps. It has a scalable pub/sub paradigm, is fault-tolerant, and has persistent storage, which makes it the foundation for many streaming designs. Kafka Connect and Kafka Streams make it easier to connect and handle data by providing connectors and processing libraries, respectively.
Structured Streaming in Apache Flink and Spark
Flink and Spark Structured Streaming provide stateful computations and complicated event processing. This lets you use windowing, join operations, and exactly-once semantics. Operators or custom sensors connect these frameworks to orchestrators.
Clarifai’s Real-Time Model Inference
Clarifai’s platform has streaming inference endpoints that can be added to pipelines. This lets you classify, recognize objects, or analyze language in real time on data streams. These endpoints operate with orchestrators like Airflow or Dagster by starting model calls when new messages come in through Kafka or Pulsar.
Important Things to Think About When Designing
- Event-Driven Triggers: Use sensors or watchers to start pipelines when files are dropped, API calls are made, or messages are sent to a queue.
- Back-Pressure Management: Streaming frameworks need to be able to manage different input rates without crashing or losing data.
- Idempotent Operations: Make sure that tasks can safely try again without doing the same work twice, especially while processing events.
- State Management: Keep track of the status of tasks to support complicated aggregations. This needs long-lasting storage and snapshotting.
- Latency Monitoring: Use metrics and alerts to find bottlenecks. Clarifai’s platform shows inference latency data for each model call.
Expert Advice
- Jay Kreps says that “real-time isn’t just about speed; it’s about making decisions as things happen.“
- Architects from Uber’s Michelangelo platform stress that orchestrators need to handle both stateless and stateful workloads for streaming to perform well.
- Clarifai’s head ML engineer says that streaming inference needs to be able to absorb spikes without crashing, and that autoscaling and batching can help keep latency low.
Example
Imagine a ride-hailing business that needs to be able to find fake travel requests right away. Every request that comes in sends a Kafka message. An orchestrator runs a pipeline that checks the user’s identity, their location, and their driver’s photographs for any strange things, and then either authorizes or rejects the ride, all in a matter of milliseconds.

How Do You Manage Data Across Both Hybrid and Multi-Cloud Environments?
What Problems Come Up When You Try to Orchestrate Many Clouds?
Multi-cloud orchestration needs to hide the variations across providers, keep track of costs and data transfers, and make sure that security and governance are the same in all environments.
The Multi-Cloud Need
To get the best performance, pricing, and reliability, businesses are using AWS, Azure, Google Cloud, and their own data centers more and more. This technique avoids being locked into a vendor and makes use of specialized services, but it also creates problems such variances in APIs, identification models, and price structures.
Problems and Answers
Abstraction and Moving
Orchestrators need to provide a single control plane so that workflows may execute on any cloud or on-premises architecture without major changesdatacamp.com. Declarative deployments across providers are possible with tools like Terraform (for IaC) and Clarifai’s compute orchestration.
Managing Costs
The costs of moving data and egress can be high, thus orchestrators should try to keep data in one place and limit how much data is moved. Processing at the edge or in a specific location lowers egress costs.
Governance and Security
To keep policies the same across clouds, you need to connect to IAM systems, encrypt data, and keep audit logs. Data virtualization and catalogs help create unified perspectives while still preserving the sovereignty of data in each region.
Things to Think About When It Comes to Networks and Latency
Cross-cloud networking might cause delays; therefore, orchestrators need to make sure that services perform well in different regions and that important services are available in all zones.
Tools and Plans
- Provider-Agnostic Orchestrators: Airflow, Dagster, and Clarifai’s compute orchestrator all work with several clouds and have plugins for each one.
- Data Fabrics and Meshes: Use data fabric architectures to hide disparities in physical storage, and use data mesh principles for decentralized ownershipmontecarlodata.com.
- Hybrid Deployment: Run orchestrators on Kubernetes clusters that span on-premises and cloud nodes. Clarifai’s on-premises runners make it possible to do local inference while connecting to cloud services.
Expert Opinions
- Corey Quinn says that you should build for portability from the start to prevent having to spend a lot of money on re-architecting later.
- The enterprise team at Clarifai says that hybrid deployment lets companies store sensitive data on their own servers while using cloud AI services for inference that needs a lot of computing power.
- Analysts say that to be successful with multi-cloud, you need to carefully plan your architecture, manage your costs, and plan how to move your data.
Example
A retail business with outlets all across India utilizes AWS to host a central data warehouse, Google BigQuery to analyze marketing data, and saves transaction data on its own servers because it has to. An orchestrator schedules nightly batch loads to AWS, starts real-time stock updates on GCP, and utilizes Clarifai’s local runner to look at CCTV footage for in-store security. All of this is done without any problems, even though the environments are different.

How Can You Make Sure That Data Orchestration Is Safe, Compliant, and Easy to See?
Quick Summary: Why Are Governance and Observability So Important?
Security and compliance keep data safe and private, but observability lets you see pipelines, which makes it easier to fix problems and enforce policies.
Basic Rules for Security and Compliance
Data orchestrators deal with private data, thus it has to be encrypted both when it is stored and when it is sent. Use role-based access control (RBAC), keep secrets safe, and keep networks separate. Make sure that solutions can interact with compliance standards like GDPR, HIPAA, and PCI-DSS, and keep audit logs of everything that happens.
GDPR’s right to be forgotten means that orchestrators must be able to remove data and metadata when asked. In businesses that are regulated, make sure that orchestrators may run completely on-premise and support data residency. Clarifai’s platform lets you deploy on-premises and has secure inference endpoints for industries that are heavily regulated.
Data Quality and Observability
Observability is more than just keeping an eye on uptime; it also means knowing how healthy the pipeline is, where the data comes from, and how good the quality metrics are. AI-powered observability systems find problems on their own, group them into types of mistakes, and recommend ways to find the root cause. Snowflake and Databricks employ machine learning to fix mistakes and sort through new data, which cuts down on the amount of work that needs to be done by hand.
Data contracts and active metadata frameworks set clear expectations between producers and consumers, making sure the data is of good quality and stopping “schema drift.” Lineage tracking helps teams figure out where data comes from and how it moves through pipelines, which helps with compliance and debugging.
Rules and Ways of Doing Things
- Take an “assume breach” approach: encrypt everything, limit access, and keep environments separate.
- Establish alerts to monitor latency, errors, and unusual data patterns continuously.
- Set up data stewardship responsibilities and make sure someone is responsible for the quality and compliance of the data.
- Use test environments, with separate dev, staging, and prod pipelines, and set up automatic promotion rules.
Governance Features of Clarifai
Clarifai’s enterprise platform has built-in observability that logs every inference call, keeps track of model versions, and shows dashboards for latency and throughput. Its role-based permissions make sure that only people who are allowed to can deploy or query models. Clarifai helps businesses satisfy strict compliance requirements by offering on-premises alternatives and encrypted endpoints.
Expert Advice
- Bruce Schneier says that “data is a toxic asset—it’s valuable but dangerous.” He urges businesses to protect their data by making sure it is not exposed too much.
- Barr Moses says that visibility is the key to reliable analytics. Without visibility, mistakes go unreported.
- Clarifai’s security lead says that AI models can be used as attack vectors, thus orchestrators need to keep an eye on how well the models work and look for inputs that are meant to hurt them.
Example
An insurance firm manages consumer data across many systems. They employ an orchestrator with built-in checks for data quality to find records that don’t match, encrypt all API calls, and keep track of every access for audits. During a compliance audit, the organization may provide end-to-end lineage and establish that sensitive data never escapes regulated environments.
What Trends Will Affect How Data Orchestration Works in the Future?
In short, what trends should you keep an eye on?
In the next few years, AI-driven orchestration, real-time analytics, data mesh architectures, serverless workflows, and self-service technologies will change how pipelines are constructed and run.
Orchestration with AI
AI takes care of boring duties like cleaning up data, finding anomalies, and figuring out what caused them. It also helps with root cause analysis. Generative AI models like ChatGPT need high-quality datasets, which makes orchestration tools have to take data quality and context into account. We will have AI helpers that can write pipeline code, suggest improvements, and adjust to fit new workloads.
Analytics in Real Time and on the Edge
Edge computing is still growing; gadgets process data on their own and transmit summaries back to central systems. This change will make orchestrators have to handle micro-batches and event-driven triggers, which will make sure that latency is low and the edge is strong.
Data Mesh and Products for Data
Organizations use data mesh designs to spread out ownership and think of data as a product. Orchestrators will have to make sure that data contracts are followed, manage pipelines across domains, and keep track of where data came from in decentralized domains. Metadata will be very important for finding and managing digital assets.
Everything-as-Code and Serverless
Temporal and AWS Step Functions are examples of serverless orchestration services that let you pay as you go and don’t require you to worry about infrastructure. Declarative methods (Everything-as-Code) let teams version workflows in git, which makes it possible for data pipelines to be reviewed and CI/CD to happen at the same time. Kestra is a good example of this trend because it uses YAML to construct workflows.
Low-Code and Self-Service
Business users are asking for more and more self-service technologies that let them develop pipelines without having to write code. Analysts may control data flows with low-code systems like Rivery or Mage (and Clarifai’s visual pipeline builder), making data engineering more accessible to everyone.
Evolution of Observability and Compliance
Active metadata and AI-driven observability will find problems before they get worse, and data contracts will make sure everyone knows what to anticipate. Rules will get stricter, and orchestrators will have to do real-time compliance audits and delete data automatically.
Expert Advice
- Fei-Fei Li says that “data will be the differentiator in AI systems; orchestrators must adapt to feed models with the right data at the right time.“
- Zhamak Dehghani says that decentralized, domain-oriented pipelines will take the place of monolithic data platforms.
- Clarifai’s CEO said that orchestration will eventually merge with model deployment platforms, making it easier for users to design, implement, and watch AI solutions.
Example
Think about a healthcare startup that is making an app for individualized nutrition. They use a data mesh design, which means that nutritionists own food data, doctors own medical records, and AI researchers own models. A serverless orchestrator starts events as fresh lab results come in, uses Clarifai’s natural language model to read doctor notes, and sends recommendations to users, all while keeping domain boundaries and data contracts in place.

What Are Some Real-Life Examples and Success Stories?
Quick Summary: How do people use orchestration in real life?
Data orchestration makes everything from smart manufacturing and personalized healthcare to recommendation engines and fraud detection possible. Success examples show real benefits, such as better data quality, faster time to insight, and lower costs.
E-Commerce: Dynamic Pricing and Recommendations
A top e-commerce site organizes data from online logs, purchase history, and social media feeds. An orchestrator starts pipelines that figure out dynamic pricing, run Clarifai’s recommendation models, and update the store in almost real time. The result was higher conversion rates and happier customers.
Finance: Finding Fraud in Real Time
Every day, banks handle millions of transactions. An orchestrator takes in transaction streams, runs models to find unusual activity, verifies the rules set by the government, and stops suspect activity in just a few seconds. One bank said that its losses from fraud went down by 35% and it was able to disclose to regulators more quickly.
Healthcare: Personalized Treatment Plans
Hospitals manage streams of computerized health information, genetic data, and data from wearable devices. Pipelines use predictive algorithms to suggest treatment regimens, set up appointments, and keep an eye on patients’ vital signs in real time. Secure orchestration makes sure that HIPAA rules are followed, while Clarifai’s on-premises inference keeps private information safe.
Smart Factories in Manufacturing
Smart factories utilize sensors to keep an eye on machines, find problems, and plan maintenance. Orchestrators take sensor data, run Clarifai models to find problems in audio and images, and automatically send out repair requests. This cuts down on downtime and makes equipment last longer.
Entertainment and Media
Streaming services like Netflix employ organized pipelines to collect data on how many people are watching, train recommendation algorithms, and send personalized content suggestions to millions of customers. Automated orchestration makes it possible to handle petabytes of data every day.
The Indian Situation
Orchestration is being used by Indian startups, especially those in fintech and healthcare, to grow their businesses. An insurance aggregator in Mumbai uses orchestrated workflows to get quotes from several companies, run risk models with Clarifai’s AI, and show users bespoke plans.
Expert Advice
- Kate Strachnyi says that data quality is really important for success stories. If pipelines aren’t set up correctly, the insights they give will be wrong.
- Clients of Clarifai say that adding model inference directly into orchestrated pipelines cuts down on development time and operational problems by a large amount.
- Vivek Muppa says that firms usually start with small orchestrated workflows and then grow them over time, learning best practices as they go.
Example
Think about a power company that puts smart meters in remote areas. A coordinated pipeline gathers consumption data, estimates peak demand, and tells power plants to change how much power they make. Clarifai’s anomaly detection model identifies irregularities that could mean tampering, and field teams are then told about them. This all-encompassing method makes things more reliable and cuts down on losses.
Step-by-Step Guide to Putting a Data Orchestration Strategy into Action
Quick Summary: What Are the Steps to Set Up Orchestration?
To put an orchestration plan into action, you need to figure out your business goals, map out your processes, design your architecture, choose your tools, create your pipelines, add observability, and promote a DataOps culture.
Steps for Implementation
Step 1: Look at Your Goals and Needs
To begin, be clear about what you want: do you need real-time fraud detection, nightly ETL, or AI inference? Find out where the data comes from, how much it is, how fast it moves, and what rules need to be followed. Get people from the business, IT, and data departments involved to agree on what is most important.
Step 2: Make a Map of Your Current Workflows
Write down how data flows, what it depends on, and where it hurts. Make flowcharts to help you see how things work and find steps that need to be done by hand. Find out how long it takes for things to happen, how often they fail, and how good the data is.
Step 3: Plan the Architecture
You can choose between batch, streaming, or hybrid architectures. Define the parts of storage (data lakes vs. warehouses), computation (spark clusters, Kubernetes, serverless), and networks. Take into account both on-premises and multi-cloud needs.
Step 4: Choose and Evaluate Tools
Use the criteria we talked about before to make a short list of tools. Use your real workloads to run proof-of-concept testing. If AI inference is a big part of your operations, think about using Clarifai’s compute orchestrator.
Step 5: Make Pipelines
Use DAGs, YAML, or visual builders to make pipelines. Follow best practices include using modular tasks, idempotent operations, parameterization, and version control. Use official SDKs or connectors to connect to Clarifai’s API.
Step 6: Set Up Monitoring and Observability
Add logs, analytics, and tracing to instrument pipelines. Use things like Prometheus, Grafana, and the dashboards that come with Clarifai. Set up alerts for problems, increases in latency, and strange data. Use contracts and tests to make sure your data is good.
Step 7: Test and Make Changes
Do unit tests, integration tests, and load tests. Check that the error management and recovery systems work. Use feedback and performance metrics to make changes. Automate the deployment of pipeline definitions with CI/CD.
Step 8: Teach Teams and Promote a DataOps Culture
Train developers, analysts, and business users on the orchestrator you picked. Set up code standards, review processes, and documentation. Encourage data engineers, ML engineers, and domain specialists to work together across departments.
Expert Opinions
- Lenny Liebmann says that for an orchestration plan to work, teams need to work together and use DevOps ideas as well as technology.
- Clarifai’s solution engineers say that to show value and get people on board, you should start with a pilot project.
- Kelsey Hightower says that to avoid mistakes by people, you should automate everything, even testing and deployment.
Example
A logistics company needs to plan deliveries and find the best routes. After that, they plan how they would take in and deliver orders, chose Prefect to handle the orchestration, add Clarifai’s route optimization model, and set up real-time monitoring for driver delays. They notice shorter delivery times and happier customers within a few months.
Conclusion: How to Get Around the Data Orchestration Landscape in 2025
Data orchestration is no longer a choice; it’s a must for businesses that want to use AI, handle real-time analytics, and work in several clouds. When choose the right tool, you need to think about how easy it is to use, how scalable it is, how well it works with other tools, how well it works in real time, how much it costs, and how secure it is. Open-source platforms like Airflow and Dagster are flexible, while enterprise solutions like ActiveBatch, RunMyJobs, and Clarifai’s compute orchestrator offer support and more advanced functionality. For the future of montecarlo data, companies need to adapt by using new tools and methods. Real-time streaming, data mesh architectures, and AI-driven observability are all changing the way things work.
To put in place a strong orchestration strategy, you need to plan carefully, test it out, keep an eye on it all the time, and have a DataOps culture where everyone works together. Clarifai’s products, like compute orchestration, model inference APIs, and local runners, work well with a lot of different orchestrators. This makes it easy for teams to design smart pipelines with no trouble. By adopting data orchestration now, your company will be able to get insights faster, make better decisions, and gain a competitive edge in the age of AI.
FAQs
- Q1: Is data orchestration the same thing as ETL?
No, ETL is just concerned with getting data, changing it, and loading it into a destination. Data orchestration, on the other hand, coordinates many operations across many systems, such as ETL, ML inference, and streaming events, making sure that dependencies are handled correctlydatacamp.com.
- Q2: Do I need to know how to code to use a data orchestrator?
It depends on the instrument. Airflow and Dagster are open-source systems that need Python. ActiveBatch and Clarifai’s UI are examples of enterprise solutions that have low-code interfaces.
- Q3: How does Clarifai work with tools for organizing data?
You may call Clarifai’s APIs and SDKs from orchestrators like Airflow and Dagster, which lets you use model inference in your pipelines. Its compute orchestrator also takes care of deploying and scaling models.
- Q4: Can I manage data across more than one cloud?
Yes, a lot of orchestrators support multi-cloud deployment. For example, Clarifai’s local runner lets you conduct inference on-premises while managing workflows across clouds, hiding differences across providers.
- Q5: What can I do to make sure I follow rules like GDPR?
Pick orchestrators that already have security features like encryption, RBAC, and audit logs. Also, set up rules for where data is stored. Clarifai’s choice to deploy on-premises helps keep sensitive data safe.
- Q6: What is the difference between data orchestration and process automation?
Workflow automation takes care of single activities or business processes. Data orchestration, on the other hand, takes care of complicated, multi-step data pipelines that entail changing, analyzing, and transporting data between systems.
- Q7: Are there ways to orchestrate data without servers?
Yes, AWS Step Functions and Temporal are examples of serverless services that let you pay as you go for orchestration without having to manage infrastructure. Kestra and other declarative tools can let you scale without a server.
- Q8: Why is observability crucial in data pipelines?
Observability lets teams find mistakes, keep an eye on performance, and make sure data is good. AI-driven observability tools can find problems on their own and fix them.
- Q9: What trends should I get ready for?
Get ready for AI-driven orchestration, real-time edge analytics, data mesh architectures, low-code tools, and serverless workflows.
- Q10: What is the first step in data orchestration?
Start by figuring out what you need, sketching out how things are done now, choosing a tool that meets your needs, and running a test project. Use Clarifai’s tools to swiftly add AI inference.
![How to Harness AI for Video Creation with Joshua Xu [MAICON 2025 Speaker Series]](https://www.fazb.com.sa/wp-content/uploads/2025/09/How-to-Harness-AI-for-Video-Creation-with-Joshua-Xu.png)

-png.png?width=1024&height=1536&name=ChatGPT%20Image%20Sep%2018%2c%202025%2c%2001_42_48%20PM%20(1)-png.png)
![How to Reframe Your AI Adoption for Real Results with Pam Boiros [MAICON 2025 Speaker Series]](https://www.fazb.com.sa/wp-content/uploads/2025/09/How-to-Reframe-Your-AI-Adoption-for-Real-Results-with.png)








.png?width=1000&height=556&name=11.8_blog_hero%20(1).png)
%20%20(2).png?width=1000&height=629&name=Output%20Speed%20vs%20Price%20(10%20Sep%2025)%20%20(2).png)
%20%20(1).png?width=1000&height=657&name=Latency%20vs%20Output%20Speed%20(10%20Sep%2025)%20%20(1).png)
![How to Turn Employee AI Use into a Strategic Advantage with Brian Madden [MAICON 2025 Speaker Series]](https://www.fazb.com.sa/wp-content/uploads/2025/09/How-to-Turn-Employee-AI-Use-into-a-Strategic-Advantage.png)





