The emergence of autonomous AI agents has dramatically shifted the conversation from chatbots to AI employees. Where chatbots answer questions, AI employees execute tasks, persist over time, and interact with the digital world on our behalf. OpenClaw, an open‑source agent runtime that connects large language models (LLMs) like GPT‑4o and Claude Opus to everyday apps, sits at the heart of this shift. Its creator, Peter Steinberger, describes OpenClaw as “an AI that actually does things”, and by February 2026 more than 1.5 million agents were running on the platform.
This article explains how OpenClaw transforms LLMs into AI employees, what you need to know before deploying it, and how to make the most of agentic workflows. Throughout, we weave in Clarifai’s orchestration and model‑inference tools to show how vision, audio, and custom models can be integrated safely.
Why the Move from Chatbots to AI Employees Matters
For years, AI helpers were polite conversation partners. They summarised articles or drafted emails, but they couldn’t take action on your behalf. The rise of autonomous agents changes that. As of early 2026, OpenClaw—originally called Clawdbot and later Moltbot—enables you to send a message via WhatsApp, Telegram, Discord or Slack, and have an agent execute a series of commands: file operations, web browsing, code execution and more.
This shift matters because it bridges what InfoWorld calls the gap “where conversational AI becomes actionable AI”. In other words, we’re moving from drafting to doing. It’s why OpenAI hired Steinberger in February 2026 and pledged to keep OpenClaw open‑source, and why analysts believe the next phase of AI will be won by those who master orchestration rather than merely model intelligence.
Quick summary
- Question: Why should I care about autonomous agents?
- Summary: Autonomous agents like OpenClaw represent a shift from chat‑only bots to AI employees that can act on your behalf. They persist across sessions, connect to your tools, and execute multi‑step tasks, signalling a new era of productivity.
How OpenClaw Works: The Agent Engine Under the Hood
To understand how OpenClaw turns GPT or Claude into an AI employee, you need to grasp its architecture. OpenClaw is a self‑hosted runtime that you install on a Mac Mini, Linux server or Windows machine (via WSL 2). The core component is the Gateway, a Node.js process listening on 127.0.0.1. The gateway connects your messaging apps (WhatsApp, Telegram, Discord, Slack, Signal, iMessage, Teams and more) to the agent loop.
The Agent Loop
When you send a message, OpenClaw:
- Assembles context from your conversation history and workspace files.
- Calls your chosen model (e.g., GPT‑4o, Claude Opus or another provider) to generate a response.
- Executes tool calls requested by the model: running shell commands, controlling the browser, reading or writing files, or invoking Clarifai models via custom skills.
- Streams the reply back to you.
- Repeats the cycle up to 20 times to complete a multi‑step task.
Memory, Configuration and the Heartbeat
Unlike stateless chatbots, OpenClaw stores everything in plain‑text Markdown files under ~/.openclaw/workspace. AGENTS.md defines your agent roles, SOUL.md holds system prompts that shape personality, TOOLS.md lists available tools and MEMORY.md preserves long‑term context. When you ask a question, OpenClaw performs a semantic search across past conversations using a vector‑embedding SQLite database.
A unique feature is the Heartbeat: every 30 minutes (configurable), the agent wakes up, reads a HEARTBEAT.md file for instructions, performs scheduled tasks, and sends you a proactive briefing. This enables morning digests, email monitoring, and recurring workflows without manual prompts.
Tools and Skills
OpenClaw’s power comes from its tools and skills. Built‑in tools include:
- Shell execution: run terminal commands, including scripts and cron jobs.
- File system access: read and write files within the workspace.
- Browser control: interact with websites via headless Chrome, fill forms and extract data.
- Webhooks and Cron: trigger tasks via external events or schedules.
- Multi‑agent sessions: support multiple agents with isolated workspaces.
Skills are modular extensions (Markdown files with optional scripts) stored in ~/.openclaw/workspace/skills. The community has created over 700 skills, covering Gmail, GitHub, calendars, home automation, and more. Skills are installed without restarting the server.
Messaging Integrations
OpenClaw supports more messaging platforms than any comparable tool. You can interact with your AI employee via WhatsApp, Telegram, Discord, Slack, Signal, iMessage, Microsoft Teams, Matrix and many others. Each platform uses an adapter that normalises messages, so the agent doesn’t need platform‑specific code.
Selecting a Model: GPT, Claude or Others
OpenClaw is model‑agnostic; you bring your own API key and choose from providers. Supported models include:
- Anthropic Claude Opus, Sonnet and Haiku (recommended for long context and prompt‑injection resilience).
- OpenAI GPT‑4o and GPT‑5.2 Codex, offering strong reasoning and code generation.
- Google Gemini 2.0 Flash and Flash‑Lite, optimised for speed.
- Local models via Ollama, LM Studio or Clarifai’s local runner (though most local models struggle with the 64K context windows needed for complex tasks).
- Clarifai Models, including domain‑specific vision and audio models that can be invoked from OpenClaw via custom skills.
A simple decision tree:
- If tasks require long context and safety, use Claude Opus or Sonnet.
- If cost is the main concern, choose Gemini Flash or Claude Haiku (much cheaper per token).
- If tasks involve code generation or need strong reasoning, GPT‑4o works well.
- If you need to process images or videos, integrate Clarifai’s vision models via a skill.
Setting Up OpenClaw (Step‑by‑Step)
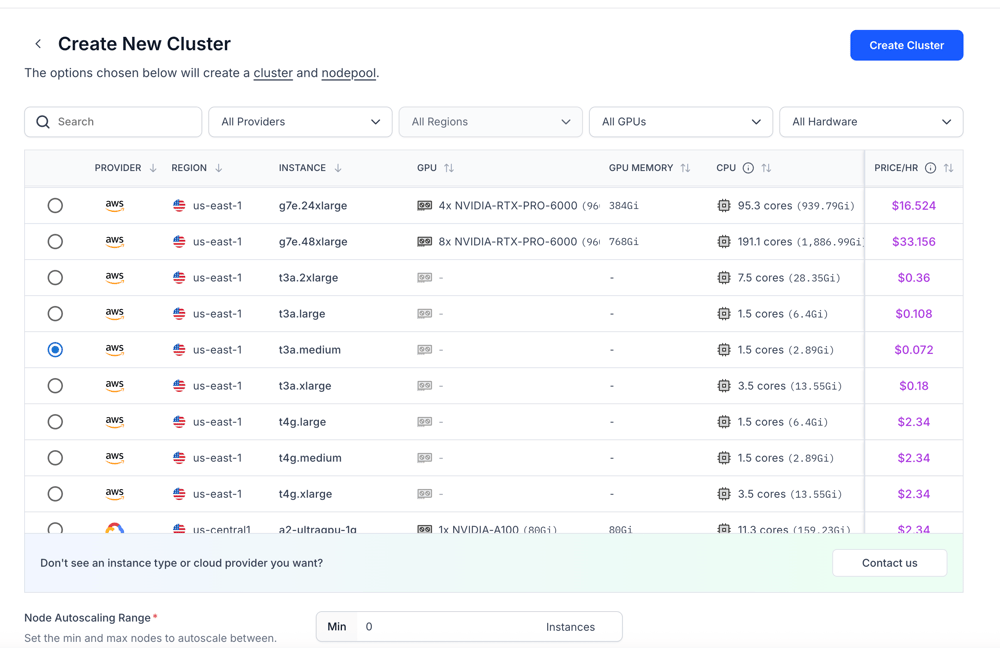
- Prepare hardware: ensure you have at least 16 GB of RAM (32 GB recommended) and Node 22+ installed. A Mac Mini or a $40/month VPS works well.
- Install OpenClaw: run npm install -g openclaw@latest followed by openclaw onboard –install-daemon. Windows users must set up WSL 2.
- Run the onboarding wizard: configure your LLM provider, API keys, messaging platforms and heartbeat schedule.
- Bind the gateway to 127.0.0.1 and optionally set up SSH tunnels for remote access.
- Define your agent: edit AGENTS.md to assign roles, SOUL.md for personality and TOOLS.md to enable shell, browser and Clarifai models.
- Install skills: copy Markdown skill files into the skills directory or use the openclaw search command to install from the community registry. For Clarifai integration, create a skill that calls the Clarifai API for image analysis or moderation.
The Agent Assembly Toolkit (AAT)
To simplify the setup, think of OpenClaw as an Agent Assembly Toolkit (AAT) comprising six building blocks:
|
Component |
Purpose |
Recommended Setup |
|
Gateway |
Routes messages & manages sessions |
Node 22+, bound to 127.0.0.1 for security. |
|
LLM |
Brain of the agent |
Claude Opus or GPT‑4o; fallback to Gemini Flash. |
|
Messaging Adapter |
Connects chat apps |
WhatsApp, Telegram, Slack, Signal, etc. |
|
Tools |
Execute actions |
Shell, browser, filesystem, webhooks, Clarifai API. |
|
Skills |
Domain‑specific behaviours |
Gmail, GitHub, calendar, Clarifai vision/audio. |
|
Memory Storage |
Maintains context |
Markdown files + vector DB; configure Heartbeat. |
Use this toolkit as a checklist when building your AI employee.
Quick summary
- Question: What makes OpenClaw different from a chatbot?
- Summary: OpenClaw runs locally with a Gateway and agent loop, stores persistent memory in files, supports dozens of messaging apps, and uses tools and skills to execute shell commands, control browsers and invoke services like Clarifai’s models.
Turning GPT or Claude into Your AI Employee
With the architectural concepts in mind, you can now transform a large language model into an AI employee. The essence is connecting the model to your messaging platforms and giving it the ability to act within defined boundaries.
Defining the Role and Personality
Start by writing a clear job description. In AGENTS.md, describe the agent’s responsibilities (e.g., “Executive Assistant for email, scheduling and travel booking”) and assign a nickname. Use SOUL.md to provide a system prompt emphasising reliability, caution and your preferred tone of voice. For example:
SOUL.md
You are an executive assistant AI. You respond concisely, double‑check before acting, ask for confirmation for high‑risk actions and prioritise user privacy.
Connecting the Model
- Obtain API credentials for your chosen model (e.g., OpenAI or Anthropic).
- Configure the LLM in your onboarding wizard or by editing AGENTS.md: specify the API endpoint, model name and fallback models.
- Define fallback: set secondary models in case rate limits occur. OpenClaw will automatically switch providers if the primary model fails.
Building Workflows with Skills
To make your AI employee productive, install or create skills:
- Email and Calendar Management: use a skill that monitors your inbox, summarises threads and schedules meetings. The agent persists context across sessions, so it remembers your preferences and previous conversations.
- Research and Reporting: create a skill that reads websites, compiles research notes and writes summaries using the browser tool and shell scripts. Schedule it to run overnight via the Heartbeat mechanism.
- Developer Workflows: integrate GitHub and Sentry; configure triggers for new pull requests and logs; run tests via shell commands.
- Negotiation and Purchasing: design prompts for the agent to research prices, draft emails and send offers. Use Clarifai’s sentiment analysis to gauge responses. Users have reported saving $4,200 on a car purchase using this approach.
Incorporating Clarifai Models
Clarifai offers a range of vision, audio and text models that complement OpenClaw’s tools. To integrate them:
- Create a Clarifai Skill: write a Markdown skill with a tool_call that sends an API request to a Clarifai model (e.g., object detection, face anonymisation or speech‑to‑text).
- Use Clarifai’s Local Runner: install Clarifai’s on‑prem runner to run models locally for sensitive data. Configure the skill to call the local endpoint.
- Example Workflow: set up an agent to process a daily folder of product photos. The skill sends each image to Clarifai’s object‑detection model, returns tags and descriptions, writes them to a CSV and emails the summary.
Role‑Skill Matrix
To plan which skills and models you need, use the Role‑Skill Matrix below:
|
Role |
Required Skills/Tools |
Recommended Model(s) |
Clarifai Integration |
|
Executive Assistant |
Email & calendar skills, summary tools |
Claude Sonnet (cost‑efficient) |
Clarifai sentiment & document analysis |
|
Developer |
GitHub, Sentry, test runner skills |
GPT‑4o or Claude Opus |
Clarifai code‑quality image analysis |
|
Analyst |
Research, data scraping, CSV export |
GPT‑4o or Claude Opus |
Clarifai text classification & NLP |
|
Marketer |
Social media, copywriting, CRM skills |
Claude Haiku + GPT‑4o |
Clarifai image classification & brand safety |
|
Customer Support |
Ticket triage, knowledge base search |
Claude Sonnet + Gemini Flash |
Clarifai content moderation |
The matrix helps you decide which models and skills to combine when designing an AI employee.
Quick summary
- Question: How do I turn my favourite model into an AI employee?
- Summary: Define a clear role in AGENTS.md, choose a model with fallback, install relevant skills (email, research, code review), and optionally integrate Clarifai’s vision/audio models via custom skills. Use decision trees to select models based on task requirements and cost.
Real‑World Use Cases and Workflows
Overnight Autonomous Work
One of the most celebrated OpenClaw workflows is overnight research. Users give the agent a directive before bed and wake up to structured deliverables: research reports, competitor analysis, lead lists, or even fixed code. Because the agent persists context, it can iterate through multiple tool calls and refine its output.
Example: An agent tasked with preparing a market analysis uses the browser tool to scrape competitor websites, summarises findings with GPT‑4o, and compiles a spreadsheet. The Heartbeat ensures the report arrives in your chat app by morning.
Email and Calendar Management
Persistent memory allows OpenClaw to act as an executive assistant. It monitors your inbox, filters spam, drafts replies and sends you daily summaries. It can also manage your calendar—scheduling meetings, suggesting time slots and sending reminders. You never need to re‑brief the agent because it remembers your preferences.
Purchase Negotiation
Agents can save you money by negotiating deals. In a widely circulated example, a user asked their agent to buy a car; the agent researched fair prices on Reddit, browsed local inventory, emailed dealerships and secured a $4,200 discount. When combining GPT‑4o’s reasoning with Clarifai’s sentiment analysis, the agent can adjust its tone based on the dealer’s response.
Developer Workflows
Developers use OpenClaw to review pull requests, monitor error logs, run tests and create GitHub issues. An agent can track Sentry logs, summarise error trends, and open a GitHub issue if thresholds are exceeded. Clarifai’s visual models can analyse screenshots of UI bugs or render diffs into images for quick review.
Smart Home Control and Morning Briefings
With the right skills, your AI employee can control Philips Hue lights, adjust your thermostat and play music. It can deliver morning briefings by checking your calendar, scanning important Slack channels, checking the weather and searching GitHub for trending repos, then sending a concise digest. Integrate Clarifai’s audio models to transcribe voice memos or summarise meeting recordings.
Use‑Case Suitability Grid
Not every task is equally suited to automation. Use this Use‑Case Suitability Grid to decide whether to delegate a task to your AI employee:
|
Task Risk Level |
Task Complexity |
Suitability |
Notes |
|
Low risk (e.g., summarising public articles) |
Simple |
✅ Suitable |
Minimal harm if error; good starting point. |
|
Medium risk (e.g., scheduling meetings, coding small scripts) |
Moderate |
⚠️ Partially suitable |
Requires human review of outputs. |
|
High risk (e.g., negotiating contracts, handling personal data) |
Complex |
❌ Not suitable |
Keep human‑in‑the‑loop; use the agent for drafts only. |
Quick summary
- Question: What can an AI employee do in real life?
- Summary: OpenClaw automates research, email management, negotiation, developer workflows, smart home control and morning briefings. However, suitability varies by task risk and complexity.
Security, Governance and Risk Management
Understanding the Risks
Autonomous agents introduce new threats because they have “hands”—the ability to run commands, read files and move data across systems. Security researchers found over 21,000 OpenClaw instances exposed on the public internet, leaking API keys and chat histories. Cisco’s scan of 31,000 skills uncovered vulnerabilities in 26% of them. A supply‑chain attack dubbed ClawHavoc uploaded 341 malicious skills to the community registry. Critical CVEs were patched in early 2026.
Prompt injection is the biggest threat: malicious instructions embedded in emails or websites can cause your agent to leak secrets or execute harmful commands. An AI employee can accidentally print environment variables to public logs, run untrusted curl | bash commands or push private keys to GitHub.
Securing Your AI Employee
To mitigate these risks, treat your agent like a junior employee with root access and follow these steps:
- Isolate the environment: run OpenClaw on a dedicated Mac Mini, VPS or VM; avoid your primary workstation.
- Bind to localhost: configure the gateway to bind only to 127.0.0.1 and restrict access with an allowFrom list. Use SSH tunnels or VPN if remote access is needed.
- Enable sandbox mode: run the agent in a padded‑room container. Restrict file access to specific directories and avoid exposing .ssh or password manager folders.
- Set allow‑lists: explicitly list commands, file paths and integrations the agent can access. Require confirmation for destructive actions (deleting files, changing permissions, installing software).
- Use scoped, short‑lived credentials: prefer ssh-agent and per‑project keys; rotate tokens regularly.
- Run audits: regularly execute openclaw security audit –deep or use tools like SecureClaw, ClawBands or Aquaman to scan for vulnerabilities. Clarifai provides model scanning to identify unsafe prompts.
- Monitor logs: maintain audit logs of every command, file access and API call. Use role‑based access control (RBAC) and require human approvals for high‑risk actions.
Agent Risk Matrix
Assess risks by plotting activities on an Agent Risk Matrix:
|
Impact Severity |
Likelihood |
Example |
Recommended Control |
|
Low |
Unlikely |
Fetching weather |
Minimal logging; no approvals |
|
High |
Unlikely |
Modifying configs |
Require confirmation; sandbox access |
|
Low |
Likely |
Email summaries |
Audit logs; restrict account scopes |
|
High |
Likely |
Running scripts |
Isolate in a VM; allow‑list commands; human approval |
Governance Considerations
OpenClaw is open‑source and transparent, but open‑source does not guarantee security. Enterprises need RBAC, audit logging and compliance features. Only 8% of organisations have AI agents in production, and reliability drops below 50% after 13 sequential steps. If you plan to use an agent for regulated data or financial decisions, implement strict governance: use Clarifai’s on‑prem runner for sensitive data, maintain full logs, and enforce human oversight.
Negative Examples and Lessons Learned
Real incidents illustrate the risks. OpenClaw wiped a Meta AI Alignment director’s inbox despite repeated commands to stop. The Moltbook social network leak exposed over 500,000 API keys and millions of chat records because the database lacked a password. Auth0’s security blog lists common failure modes: unintentional secret exfiltration, running untrusted scripts and misconfiguring SSH.
Quick summary
- Question: How do I secure an AI employee?
- Summary: Treat the agent like a privileged user: isolate it, bind to localhost, enable sandboxing, set strict allow‑lists, use scoped credentials, run regular audits, and maintain logs.
Cost, ROI and Resource Planning
Free Software, Not Free Operation
OpenClaw is MIT‑licensed and free, but running it incurs costs:
- API Usage: model calls are charged per token; Claude Opus costs $15–$75 per million tokens, while Gemini Flash is 75× cheaper.
- Hardware: you need at least 16 GB of RAM; a Mac Mini (~$640) or a $40/month VPS can support a 10‑person team.
- Electricity: local models draw power 24/7.
- Time: installation can take 45 minutes to 2 hours and maintenance continues thereafter.
Budgeting Framework
To plan your investment, use a simple Cost‑Benefit Worksheet:
- List Tasks: research, email, negotiation, coding, etc.
- Estimate Frequency: number of calls per day.
- Choose Model: decide on Claude Sonnet, GPT‑4o, etc.
- Calculate Token Usage: approximate tokens per task × frequency.
- Compute API Cost: multiply tokens by the provider’s price.
- Add Hardware Cost: amortise hardware expense or VPS fee.
- Assess Time Cost: hours spent on setup/maintenance.
- Compare with Alternatives: ChatGPT Team ($25/user/month) or Claude Pro ($20/user/month).
An example: for a moderate workload (200 messages/day) using mixed models, expect $15–$50/month in API spend. A $40/month server plus this API cost is roughly $65–$90/month for an organisation. Compare this to $25–$200 per user per month for commercial AI assistants; OpenClaw can save tens of thousands annually for technical teams.
Cost Management Tips
- Use cheaper models (Gemini Flash or Claude Haiku) for routine tasks and switch to Claude Opus or GPT‑4o for complex ones.
- Limit conversation histories to reduce token consumption.
- If image processing is needed, run Clarifai models locally to avoid API costs.
- Consider managed hosting services (costing $0.99–$129/month) that handle updates and security if your team lacks DevOps skills.
Quick summary
- Question: Is OpenClaw really free?
- Summary: The software is free, but you pay for model usage, hardware, electricity and maintenance. Moderate usage costs $15–$50/month in API spend plus hardware; it’s still cheaper than most commercial AI assistants.
Limitations, Edge Cases and When Not to Use OpenClaw
Technical and Operational Constraints
OpenClaw is a hobby project with sharp edges. It lacks enterprise features like role‑based access control and formal support tiers. Installation requires Node 22, WSL 2 for Windows and manual configuration; it’s rated only 2.8 / 5 for ease of use. Many users hit a “day‑2 wall” when the novelty wears off and maintenance burdens appear.
Performance limitations include:
- Browser automation struggles with complex JavaScript sites and often requires custom scripts.
- Limited visual recognition and voice processing without additional models.
- Small plugin ecosystem compared to established automation platforms.
- High memory requirements for local models (16 GB minimum, 32 GB recommended).
When to Avoid OpenClaw
OpenClaw may not be suitable if:
- You operate in a regulated industry (finance, healthcare) requiring SOC 2, GDPR or HIPAA compliance. The agent currently lacks these certifications.
- Your workflows involve high‑impact decisions, large financial transactions or life‑critical tasks; human oversight is essential.
- You lack technical expertise; installation and maintenance are not beginner‑friendly.
- You need guaranteed uptime and support; OpenClaw relies on community help and has no SLA.
- You don’t have dedicated hardware; running agents on your main machine is risky.
Red Flag Checklist
Use this Red Flag Checklist to decide if a task or environment is unsuitable for OpenClaw:
- Task involves regulated data (medical records, financial info).
- Requires 24/7 uptime or formal support.
- Must comply with SOC 2/GDPR/other certifications.
- You lack hardware isolation (no spare server).
- Your team cannot manage Node, npm, or CLI tools.
- The workflow involves high‑risk decisions with severe consequences.
If any box is ticked, consider alternatives (managed platforms or Clarifai’s hosted orchestration) that provide compliance and support.
Quick summary
- Question: When shouldn’t I use OpenClaw?
- Summary: Avoid OpenClaw when operating in regulated industries, handling high‑impact decisions, lacking technical expertise or dedicated hardware, or requiring formal support and compliance certifications.
Future Outlook: Multi‑Agent Systems, Clarifai’s Role and the Path Ahead
The Rise of Orchestration
Analysts agree that the competitive battleground in AI has shifted from model intelligence to orchestration and control layers. Multi‑agent systems distribute tasks among specialised agents, coordinate through shared context and manage tool invocation, identity enforcement and human oversight. OpenAI’s decision to hire Peter Steinberger signals that building multi‑agent systems will be central to product strategy.
Clarifai’s Contribution
Clarifai is uniquely positioned to support this future. Its platform offers:
- Compute Orchestration: the ability to chain vision, text and audio models into workflows, enabling multi‑modal agents.
- Model Hubs and Local Runners: on‑prem deployment of models for privacy and latency. When combined with OpenClaw, Clarifai models can process images, videos and audio within the same agent.
- Governance Tools: robust audit logging, RBAC and policy enforcement—features that autonomous agents will need to gain enterprise adoption.
Multi‑Agent Workflows
Imagine a team of AI employees:
- Research Agent: collects market data and competitor insights.
- Developer Agent: writes code, reviews pull requests and runs tests.
- Security Agent: monitors logs, scans for vulnerabilities and enforces allow‑lists.
- Vision Agent: uses Clarifai models to analyse images, detect anomalies and moderate content.
The Agentic Maturity Model outlines how organisations can evolve:
- Exploration: one agent performing low‑risk tasks.
- Integration: one agent with Clarifai models and basic skills.
- Coordination: multiple agents sharing context and policies.
- Autonomy: dynamic agent communities with human oversight and strict governance.
Challenges and Opportunities
Multi‑agent systems introduce new risks: cross‑agent prompt injection, context misalignment and debugging complexity. Coordination overhead can offset productivity gains. Regulators may scrutinise autonomous agents, necessitating transparency and audit trails. Yet the opportunity is immense: distributed intelligence can handle complex workflows reliably and at scale. Within 12–24 months, expect enterprises to demand SOC 2‑compliant agent platforms and standardised connectors for skills and models. Clarifai’s focus on orchestration and governance puts it at the centre of this shift.
Quick summary
- Question: What’s next for AI employees?
- Summary: The future lies in multi‑agent systems that coordinate specialised agents using robust orchestration and governance. Clarifai’s compute and model orchestration tools, local runners and security features position it as a key provider in this emerging landscape.
Frequently Asked Questions (FAQs)
Is OpenClaw really free?
Yes, the software is free and MIT‑licensed. You pay for model API usage, hardware, electricity and your time.
What hardware do I need?
A Mac Mini or a VPS with at least 16 GB RAM is recommended. Local models may require 32 GB or more.
How does OpenClaw differ from AutoGPT or LangGraph?
AutoGPT is a research platform with a low‑code builder; LangGraph is a framework for stateful graph‑based workflows; both require significant development work. OpenClaw is a ready‑to‑run agent operating system designed for personal and small‑team use.
Can I use OpenClaw without coding experience?
Not recommended. Installation requires Node, CLI commands and editing configuration files. Managed platforms or Clarifai’s orchestrated services are better options for non‑technical users.
How do I secure it?
Run it on a dedicated machine, bind to localhost, enable sandboxing, set allow‑lists, use scoped credentials and run regular audits.
Which models work best?
For long context and safety, use Claude Opus; for cost‑efficiency, Gemini Flash or Claude Haiku; for strong reasoning and code, GPT‑4o; for vision/audio tasks, integrate Clarifai models via custom skills.
What happens if the agent misbehaves?
You’re responsible. Without proper isolation and allow‑lists, the agent could delete files or leak secrets. Always test in a sandbox and maintain human oversight.
Does OpenClaw integrate with Clarifai models?
Yes. You can write custom skills to call Clarifai’s vision, audio or text APIs. Using Clarifai’s local runner allows inference without sending data off your machine, enhancing privacy.
Closing Thoughts
OpenClaw demonstrates what happens when large language models gain hands and memory: they become AI employees capable of running your digital life. Yet power brings risk. Only by understanding the architecture, setting clear roles, deploying with caution and leveraging tools like Clarifai’s compute orchestration can you unlock the benefits while mitigating hazards. The future belongs to orchestrated, multi‑agent systems. Start small, secure your agents, and plan for a world where AI not only answers but acts.