Patient engagement is regularly perceived as an abstract concept, which can be somehow improved by distant care technologies, such as patient portals and mHealth applications. However, as long as this concept keeps its abstract nature, it is challenging to get the actionable information on how much patients are engaged and if there’s growth or decrease of their involvement level over time. It is also difficult to evaluate the impact of separate channels that are used to engage patients.
Of course, this situation cannot satisfy healthcare providers on their way to value-based care delivery, where patient engagement plays a significant role.
Hopefully, there’s nothing unmeasurable in the healthcare data analytics world. Providers can transform the abstract concept into a measurable value that will assist them in fact-based decision making, allowing to elicit the effective channels, understand what triggers patients’ attention and see the real picture of patient engagement. Let’s see how it can be done.
Guidelines for measuring patient engagement
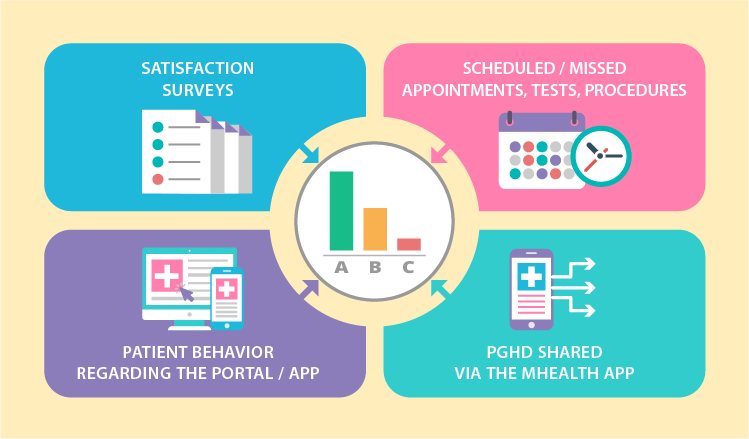
To equip healthcare providers with valuable insights on patient engagement levels, data analytics needs to harness the following 4 information flows:
- Satisfaction surveys
- Scheduled / missed appointments, tests, procedures
- Patient behavior regarding the portal / app
- PGHD shared via the mHealth app
By analyzing each flow separately as well as in combination, it is possible to range patients according to their level of involvement. For example, it can be an ABC rating, where patients with maximum engagement levels form the ‘A’ group. Accordingly, underengaged patients hit into ‘B’ and ‘C’. We came up with the following options for ranging patients.
Note: Where no particular values are advised in the examples below, the measures may vary according to a particular healthcare organization and its patients.
The frequency of patient portal logging in / mobile app launching

Applicable to all patient groups. Here, the estimated values for groups ‘A’ and ‘B’ overlap as the target frequency may change depending on a provider.
- ‘A’: high frequency – a few times a day, daily or weekly
- ‘B’: medium frequency – daily, weekly, monthly
- ‘C’: low or no frequency – rare, down to a few times a year
The scope of patient portal / mobile app features used
Applicable to all patient groups. This criterion is useful to highlight the interests of relatively healthy patients, define the services they can benefit from and reach out to them via the app or the portal they use. Depending on the available functionality, the feature scope can include vitals and medication tracking, calorie counter, treatment goal setting, rehabilitation (physical, pulmonary, post-surgery and more) support, etc. It’s estimated that an app or a portal contains several feature scopes, and each one is evaluated separately.
- ‘A’: high use
- ‘B’: medium
- ‘C’: low or none
The percentage of completed appointments
Applicable to all patient groups.
- ‘A’: 80 – 100% of completed appointments
- ‘B’: 60 – 80% of completed appointments
- ‘C’: less than 60% of completed appointments
Attendance of recommended follow-up appointments
Applicable to all patient groups. This criterion shows how engaged a patient is according to his or her attitude to follow-up appointments, for example, when a physician recommends an individual to come back every 6 months for a regular checkup.
- ‘A’: 70 – 100% of recommended appointments are completed within 1-2 months from the planned date
- ‘B’: less than 70% are completed within 1-2 months
- ‘C’: less than 30% are completed within 1-2 months
PGHD sharing
Recommended for chronic and post-operative patients. There is also a possibility to pick one target PGHD measure for a certain disease (the blood glucose level for diabetes, SpO2 for COPD).
- ‘A’: sharing is regular. The target frequency should be individually configured for particular patient groups. For example, patients with diabetes can share their blood glucose a few times a day, while COPD patients will share their oximetry results once or twice a week.
- ‘B’: inconsistent sharing, some gaps in measurements (interrupted measurements, incomplete data, systematic errors, etc.).
- ‘C’: patient makes significant gaps in measurements, which interfere with the adequate health status evaluation.
Adherence to the medication plan
Applicable to patient groups with treatment plans and medication intake schemes delivered via a mobile app or a portal. However, it is recommended to track medication intake via an app with a preset medication timer.
- ‘A’: 80 – 100% of prescribed medications is taken within the day
- ‘B’: 50 – 80% of medications is taken within the day
- ‘C’: less than 50% of medications is taken within the day
Evaluation of physical activities
Applicable to all patient groups. We suggest setting different and sometimes even individual activity targets for patients with certain conditions. A physical activity can be evaluated via data flows from a smartphone’s default pedometer as well as wearables connected to the mobile patient app.
- ‘A’: a patient’s actual physical activity is 70 – 100>% of the target
- ‘B’: the actual activity is 50 – 70% of the target
- ‘C’: less than 50% of the target
Survey participation ratio
Applicable to all patient groups. Individuals can receive various surveys to fill in, and the topics can vary as well. Therefore, we suggest not to focus on particular figures but rather go for the ratio of completed-to-received surveys.
- ‘A’: a patient completes 60 – 100% of the surveys received in the last 12 months
- ‘B’: a patient completes 30 – 60% of the surveys received in the last 12 months
- ‘C’: a patient completes less than 30% of the surveys received in the last 12 months
Dimensions to segment patients
We mentioned that patient engagement is rooted in personal connections, but it is also affected by an array of different events that individuals undergo daily. While it is impossible to track all events, healthcare providers can turn to information they already have and tie level of patient involvement with patients’ health profiles and clinical data. The process of tying should be also carried out by healthcare data analytics system.
To facilitate the process of creating patient segments that can be used to correlate with patient engagement, we came up with a few possible dimensions. In this concept, all the dimensions are equally important. They can be used together, separately or in different combinations, so that providers could go with wider segments or narrow them down.

Facility
Depending on a health organization’s size, patients can receive services across different facilities and locations. It can be useful to elicit the areas where patients lack engagement and then fix the situation.
Example 1. Outpatient facilities:
- Oklahoma City, OK
- Stillwater, OK
- Edmond, OK and more
Example 2. Inpatient facilities:
- Boston, MA
- Worcester, MA
- Springfield, MA and more
Example 3. Hospitals, clinics, other facilities:
- Louisville, KY
- Indianapolis, IN
- Fort Wayne, IN and more
Therapeutic departments
As departments vary among health organizations, the list will be tailored to a particular provider. Patients can be filtered down to a one department or a few at once. For example, patients with COPD and heart problems can receive service in both pulmonology and cardiology departments.
- Cardiology
- Endocrinology
- Gastroenterology
- Ophthalmology
- Pulmonology
- Orthopedics
- ENT and more
Disease status
Providers can either combine the ‘disease status’ with ‘therapeutic departments’ criteria sets or use them separately. In this set there are multiple dimensions that aren’t necessarily sufficient for the clinical-only purpose, yet they still help providers to either narrow or widen the target group. Again, each set of criteria can and should be adjusted according to provider.
Disease status:
- acute
- subacute
- chronic (each section can be drilled down to specific conditions, pathologies, disorders, etc.)
Comorbidities:
- yes (can be filtered to a list of particular diseases)
- no
Outcomes:
- recovery
- complications / exacerbations (can be filtered to a particular negative outcome)
Disabilities:
- yes (can be filtered to a specific disability)
- no
The need for systematic supervision:
- yes (then the list of exact supervision types, e.g. regular follow-up appointments or home care, can be provided)
- no
Gender / Age
The following structure of basic demographics is built by revising the Erikson’s stages of human development along with Daniel Levinson’s and Carl Jung’s theories altogether. These multiple sources hold a bit different approaches, so our outcome here is aimed to aggregate various opinions, reflect both psychological and physical development, and allow healthcare providers to narrow down the patient segments to work with.
Adults:
Woman / Man:
Binding patient engagement levels to dimensions: Opportunities
The possibilities of measuring patient engagement and tying it to different dimensions of patient health profile are exciting. Let’s review a few of them.
For example, if providers want to spot the most effective channel (app vs. portal) for involving patients, they can compare equal dimensions from the list presented above, such as frequency of patient portal logging in and mobile app launching within their ‘A’-level group. They can also apply these measures to a particular facility or through departments, because this can show preferences among patients with different conditions. Each new criteria set added makes data analytics more complex and elicits new insights that can be further applied to enhancing care delivery and improving patients’ health outcomes.
Speaking of outcomes, when providers elaborate on significant measures for health outcomes analytics (such as life quality, exacerbation rates, blood pressure control and more) under CMS reporting policy or for internal performance evaluation, it also becomes possible to track multiple dependencies. While it seems logical that higher patient engagement equals in better health outcomes, results might be surprising, and they can give a hint on areas for further improvement.
Being a king when kingdom comes
Let’s look at the bigger picture. Value-based care replaces FFS reality little by little. While programs and models that are aimed to ease up the transition (such as ACOs), still use FFS payments, their goal is to keep patients healthy, prevent exacerbations, admissions, readmissions and improve patient health outcomes. And patient engagement is a strong link in this chain, especially when it is measured.
Accordingly, analyzing patient engagement and integrating it with other healthcare data analytics dimensions providers already use means taking the lead and reaping the subsequent benefits ahead of the competition.
Get details here
Medical Data Analytics and Consulting by ScienceSoft
Analytics turns medical data into a treasure trove. Don’t miss a chance to boost patient satisfaction, optimize costs and improve internal processes.