Think of a professional athlete. What separates elite performers is what happens between games: continuous refinement, adjusting to new opponents and sharpening skills based on what the last game exposed.
Agentic AI works the same way. A model is no longer asked for an answer. It’s given a goal and has to keep adapting as environments shift, edge cases emerge and tools change. Unlike a generative model responding to a prompt, an agentic model must plan, use different tools and recover from problems it encounters mid-run.
That’s why post-training, the phase that refines a model after initial training on raw data, is no longer a one-time finishing step. It’s continuous, because the environment that agentic models operate in shifts fast. The tools an agent uses can change week to week. Edge cases surface in production that no test set anticipated. Each deployment brings its own codebase, policies and environment.
Post-training runs loop back from production as new problems surface. The compute footprint grows not because any single run is larger, but because the runs never stop. Agentic AI introduces a new compute pattern for post-training, making it the central workload of the agentic era and the primary driver of intelligence per dollar.
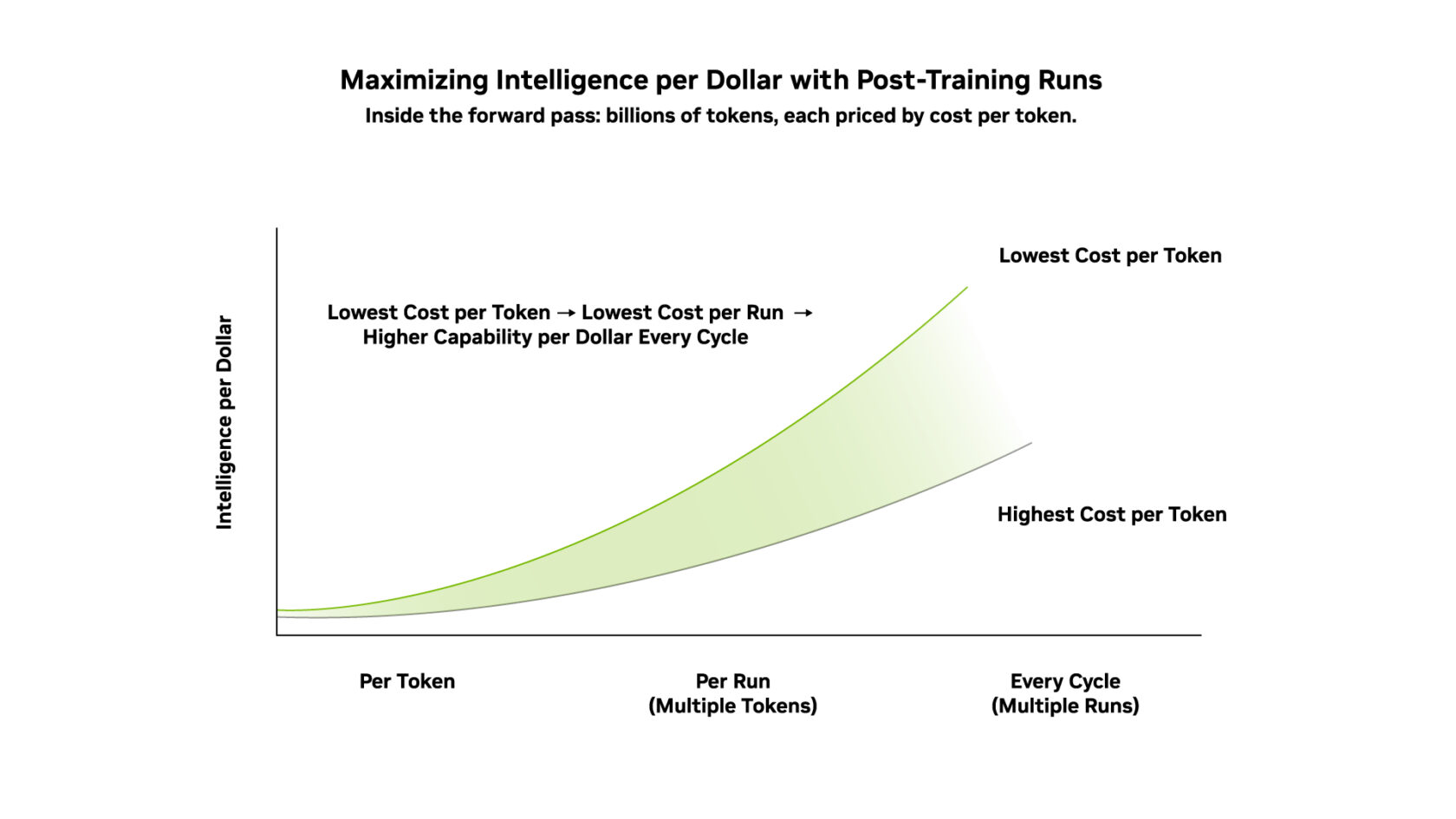
The goal of post-training is to maximize intelligence per dollar by maximizing the yield of every forward and backward pass in the continuous learning cycle. The forward pass — inference — is measured in cost per token. That means that every improvement to cost per token flows directly into intelligence per dollar.
Agentic Post-Training Demystified
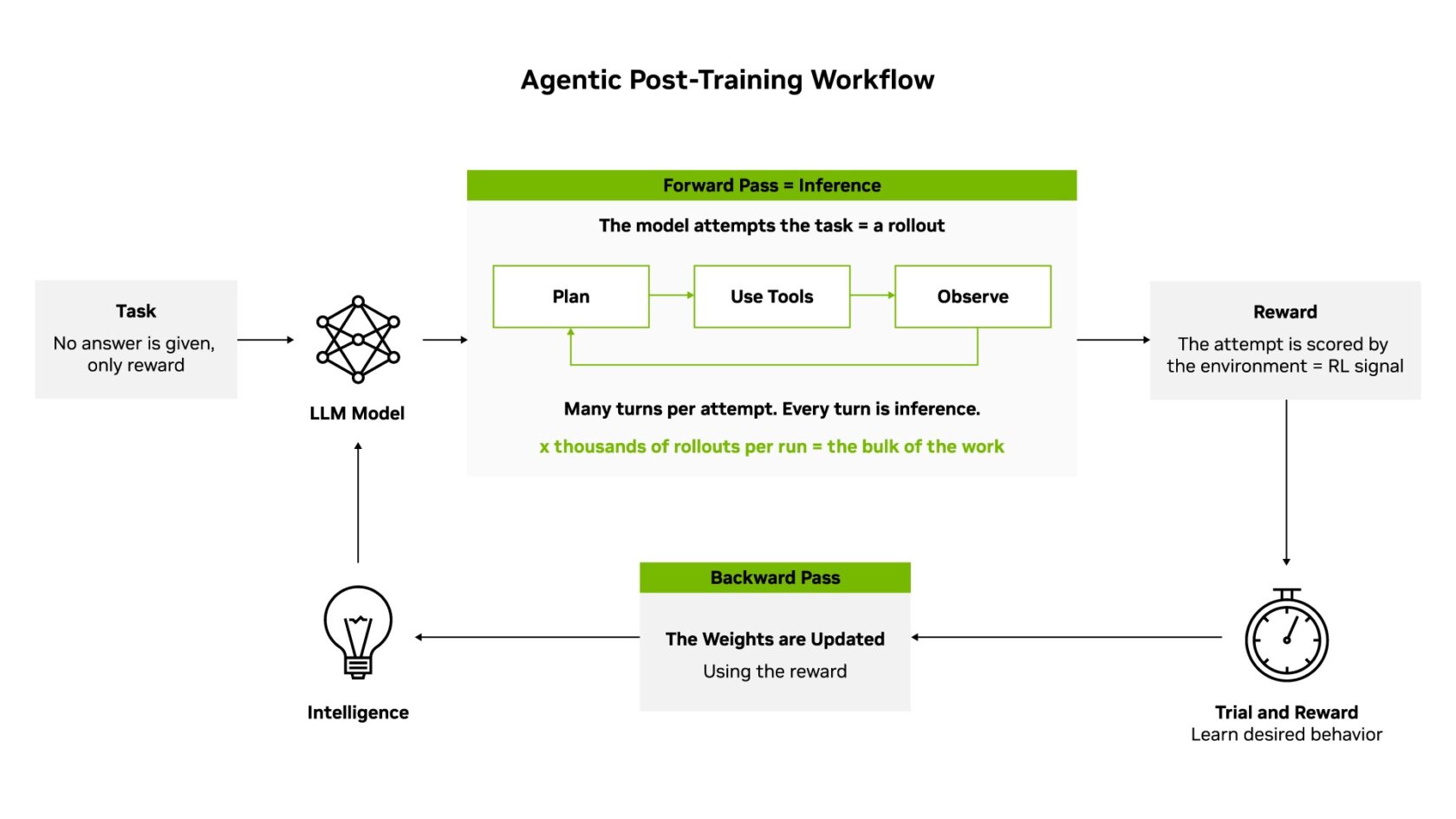
Post-training is where intelligence is built. In pretraining, the model learns to predict the next token, which gives it fluency but not intelligence. Post-training is where it learns to write code, plan a multistep task, use a search tool and recover when something goes wrong. Inference is what comes after: the model working on the job, priced in cost per token.
Because there’s no answer key to memorize, only a reward, the model learns by reinforcement learning (RL) techniques. When given a task, it writes out an attempt — the forward pass — the same work it does on the job. The attempt is scored, and the lesson updates the model’s weights — the backward pass. Across millions of attempts, intelligence grows.
Each step is compute intensive, and running this loop at scale is an orchestration problem: thousands of environments generating rollouts in parallel, rewards being verified and updated weights flowing back into training with accelerators fully utilized. NVIDIA NeMo open libraries, such as NeMo Gym for training environments and NeMo RL for distributed post-training, turn post-training from bespoke research code into repeatable infrastructure.
Why Intelligence per Dollar Extends Cost per Token
If inference is the revenue engine, post-training is the multiplier: the more capable the model, the higher the value of every token served.
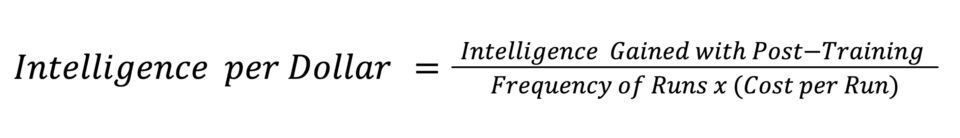
Cost per token is the key metric for the inference factory: the all-in cost of delivering 1 million tokens. Intelligence per dollar sits one layer up, answering a different question: what does it cost to build a model worth serving, and keep it worth serving as its environment changes?
The two are nested, not competing. AI infrastructure that lowers cost per token also lowers the cost of every point of intelligence built into the model. And every point of intelligence built in raises the value of every token the inference factory serves.
In other words, cost per token measures operating yield; intelligence per dollar measures whether the investment in model intelligence is paying off.
Maximizing Intelligence per Dollar: Post-Training Nemotron 3 Ultra
NVIDIA Nemotron 3 Ultra — an open weight, 550-billion-parameter mixture-of-experts (MoE) model, offers verifiable benchmarks and a fully disclosed post-training recipe run on NeMo RL. It scored 71.7% on a standard real-world coding benchmark, SWE-bench verified, where it produced a working fix for roughly seven in 10 real software bugs from open source projects, each one checked against the project’s own tests.
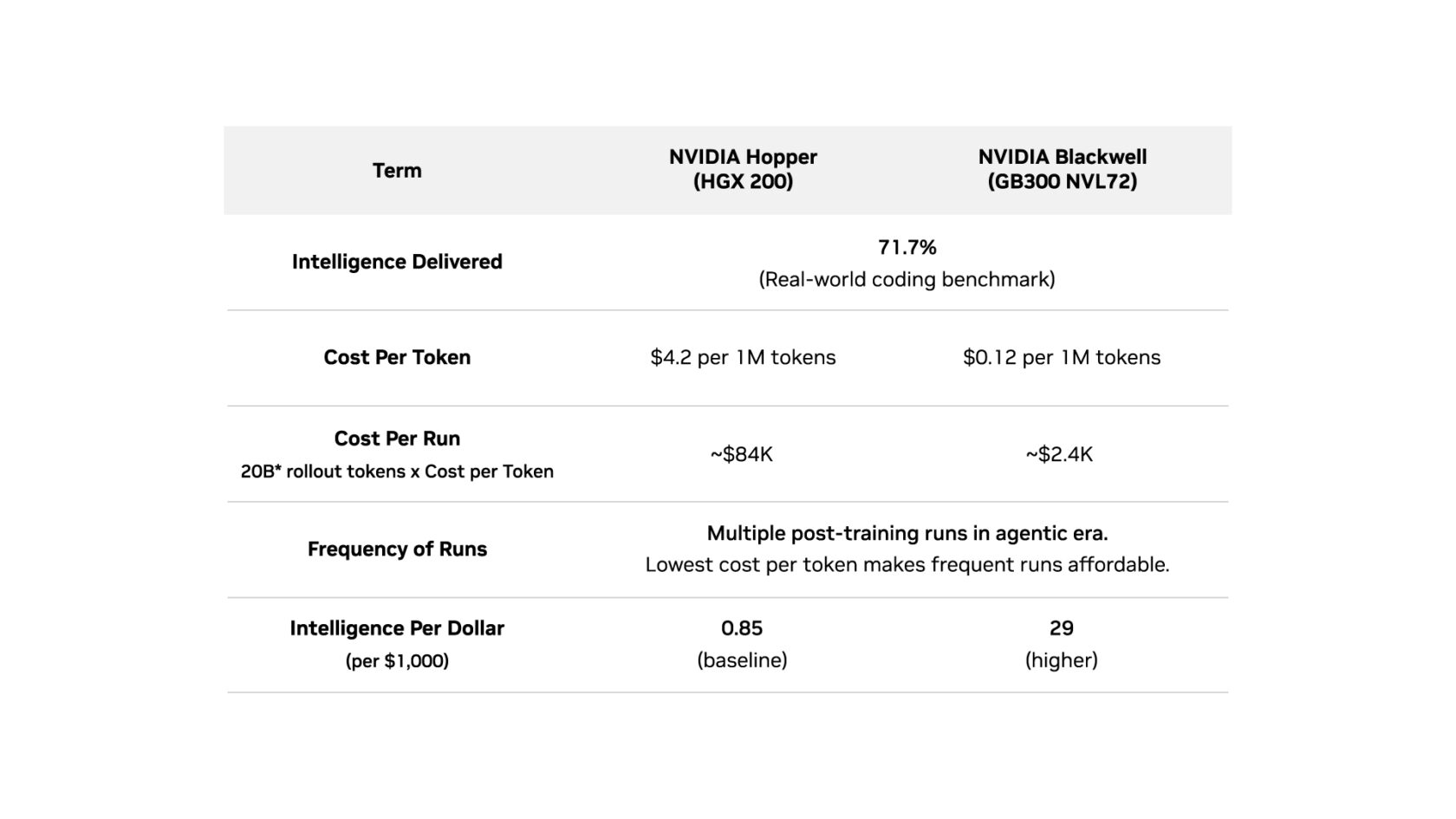
The NVIDIA Blackwell platform lowers cost per run and makes the frequent post-training the agentic era demands economically viable. That intelligence is reaped across every token served.
The NVIDIA Vera Rubin platform extends the trajectory further, training the largest models with one-fourth the GPUs of the Blackwell generation. It was codesigned from end to end to maximize intelligence per dollar for the agentic post-training load: more rollouts per run, more environments in play and post-training cycles that never stop.
Post-Training Workflows in Action
Prime Intellect’s Lab continuously post-trains frontier open models on NVIDIA Blackwell and uses NVIDIA Dynamo for inference orchestration. With Vera Rubin, Prime Intellect plans to scale reinforcement learning environments, generate more rollouts per run and accelerate training-to-inference iteration loops to maximize intelligence per dollar for businesses.
Prime Intellect has optimized its sandbox infrastructure to integrate with NVIDIA Vera CPUs, enabling low-latency, energy-efficient reinforcement learning. Open source tools and models such as NVIDIA Nemotron and NVIDIA NeMo Gym are also integrated into its software stack. When comparing realistic RL sandbox workloads against alternative x86 architectures, Prime Intellect found that Vera delivers, on average, 30% greater throughput per CPU.
Perplexity’s RL post-training stack runs asynchronously across hundreds of NVIDIA GPUs, with an RDMA-based weight transfer engine that syncs trillion-parameter models in under two seconds between training and inference compute nodes. The resulting post-trained Qwen3 235B models are then served on NVIDIA GB200 NVL72 systems.
Together AI provides post-training as a service, including supervised fine-tuning, RL and direct preference optimization. The service is delivered via a feature-rich application programming interface and software development kit that supports the full range of post-training on its AI Native Cloud platform. It has been running on NVIDIA’s platform and optimized kernel libraries, and is looking to harness the Vera Rubin platform next.
Learn more about NVIDIA Vera Rubin, the platform for AI factories to maximize intelligence per dollar across workloads. And explore NVIDIA’s full-stack platform for training frontier models.