
AgentPerf from Artificial Analysis, the industry’s first agentic AI benchmark, gives developers, enterprises and infrastructure providers a clear way to compare systems for agentic AI. In the first round of published results, the NVIDIA Blackwell Ultra NVL72 platform delivers leading performance across the agentic AI workloads tested, running 20x more agents per megawatt than NVIDIA Hopper.
Agentic AI is a fundamentally different workload than conversational AI. A single chat completion is a sprint: one large language model (LLM) call, one response. An agent functions more like a relay: It breaks a goal into many steps and keeps going until the task is done.
That results in dozens to hundreds of LLM calls chained together, each passing growing context to the next, with tool calls like code compile and execution, database search and web browsing at every handoff. The complexity isn’t additive; it’s multiplicative.
The distinction matters enormously for performance measurement. Existing AI inference benchmarks measure one LLM call: how fast an LLM responds to a single request and how many simultaneous requests a system can handle. They weren’t designed for agentic workloads, where chained LLM calls, tool call delays and growing context stress accelerated computing systems in fundamentally different ways than a single LLM call ever could.
For companies building and deploying agents at scale, it’s important to understand how responsive agents are, how many can be deployed simultaneously and how much useful work AI infrastructure can deliver for every dollar and watt invested.
NVIDIA GB300 NVL72 Runs 20x More Agents per Megawatt
In this first round, AgentPerf measures agentic performance with DeepSeek V4 Pro, a large mixture-of-experts (MoE) model that represents the class of frontier models powering today’s most capable agents. On this workload, NVIDIA GB300 NVL72 delivers the highest performance in the benchmark, running up to 20x more agents per megawatt than the NVIDIA HGX H200 system.
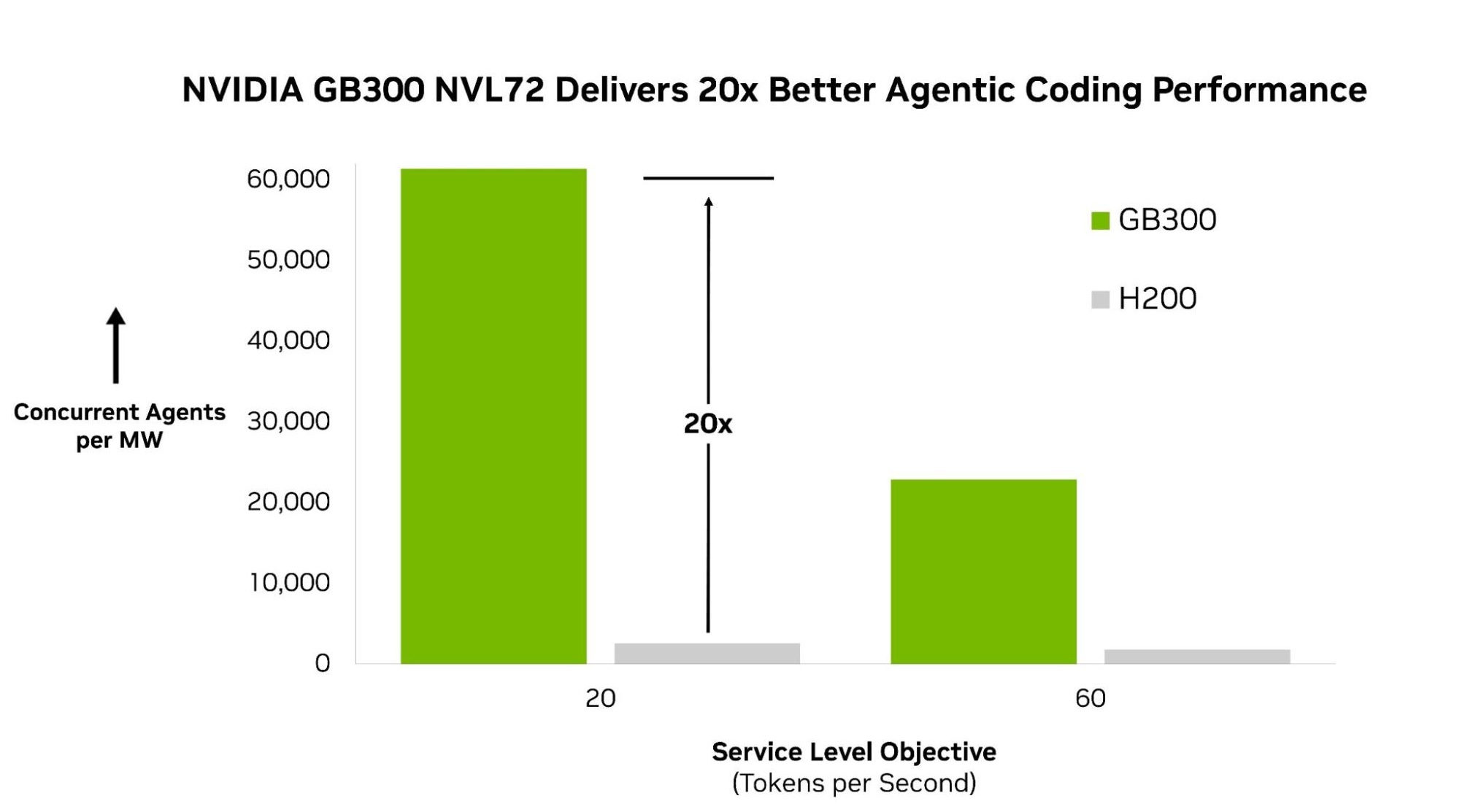
The performance advantage comes from extreme codesign across the full stack. GB300 NVL72 connects 72 GPUs into a single rack-scale system, enabling large MoE models like DeepSeek V4 Pro to distribute model execution efficiently at scale.
CUDA kernels accelerate this further by overlapping communication and compute, so the cost of coordinating across experts is absorbed rather than added to latency.
NVIDIA TensorRT LLM sustains efficiency as concurrent agent sessions scale. For example, it separates the processing of inputs from the generation of outputs so each can be optimized independently.
These results are grounded in a benchmark methodology built from the ground up to reflect how agentic AI actually works in production.
Artificial Analysis AgentPerf: Built on Real-World Agentic Workloads
AgentPerf is built based on real coding agent trajectories: an agent receives a task, reads files, writes and edits code, executes commands and iterates based on the results — all drawn from real public code repositories across 12+ programming languages. The long sequence lengths, tool call patterns and delays are all representative of real-world coding workflows.
AgentPerf then measures how many of these agentic tasks a platform can support simultaneously while meeting defined performance thresholds for responsiveness and output token rate. Tool calls are not executed but simulated using representative CPU processing time, so differences in results reflect accelerated computing performance only.
The results translate directly into infrastructure decisions: how many concurrent agentic tasks can be run per accelerator and per megawatt of power. For enterprises deploying AI agents at scale, those numbers determine how much productive work a given infrastructure investment can actually deliver.
NVIDIA Ecosystem Partners Harness Blackwell’s Leading Performance
Leading inference providers including Baseten, DeepInfra and Together AI are already serving agentic workloads on frontier models such as DeepSeek V4 Pro on NVIDIA Blackwell and powering production agentic applications today.
Together AI powers real-time inference for Cursor, an AI-powered agentic coding platform, on NVIDIA Blackwell. Cursor’s agents debug issues, generate features and execute refactors while developers continue working.
DeepInfra powers Pam.ai, an AI workforce platform for car dealerships, which deploys agents to book service appointments, handle calls and run outbound sales campaigns, entirely on NVIDIA Blackwell.
As NVIDIA and the open source ecosystem continue to optimize inference software, performance and efficiency on agentic workloads will only improve. The NVIDIA Vera Rubin architecture is now in full production, bringing the next generation of infrastructure capacity to meet the growing demands of agentic AI at scale.
Dive deeper into AgentPerf’s methodology and NVIDIA’s full-stack optimizations for agentic AI in this technical blog.







