Companies are asking how to build specialized AI that fits with the way their workflows actually run.
The first wave of enterprise AI was about access. Companies experimented with new frontier and open models, ran pilots and explored how AI can help.
Now, specialized agents — systems of models that can reason, use tools and take action even for the most complex workflows — put more useful AI within reach of the people who already know the work best.
Agents are already helping life sciences researchers accelerate medicine discovery, security teams investigate vulnerabilities with more context and operations teams seamlessly coordinate supply chains.
To tap into these specialized agents, businesses are using a foundation they can adapt and own: one built on models they can customize, tools that connect to systems they already use and infrastructure that lets agents operate safely at scale.
NVIDIA Agent Toolkit — comprising models, tools, skills and a secure runtime — provides an open, modular foundation for building safer, faster, lower-cost digital AI coworkers that enterprises and developers can customize, specialize, control and trust.
The Building Blocks for Specialized AI Coworkers
Enterprises and developers building secure, specialized AI agents require:
Models, which provide the reasoning foundation.
Tools and skills, which connect agents to the actions and domain expertise needed to get work done.
Runtime support, which helps agents execute workflows.
NVIDIA Agent Toolkit includes all three:
NVIDIA Nemotron open models give teams flexibility to customize, evaluate and deploy agents for their own needs.
NVIDIA NemoClaw blueprints provide patterns for safer agent behavior, delivering accurate results at lower costs, with tools and skills connecting agents to concrete actions.
The NVIDIA OpenShell runtime helps agents operate safely inside the systems where work gets done.
NVIDIA technologies accelerate all the pieces needed to turn a powerful frontier model into a fully functional digital coworker. The toolkit’s users can work with third-party agent harnesses — or agent orchestration frameworks — of their choice, including Hermes Agents and OpenClaw.
This unlocks enterprise AI momentum with control. And that matters because the most valuable agents across industries will be specialized.
Agents Take Shape Across Industries
The specialized AI foundation is already at work.
In life sciences, agents can help researchers call domain models for protein design, virtual screening, genomics analysis and biomarker discovery. The new NVIDIA BioNeMo Toolkit enables work that previously took months to be completed in days.
In healthcare, agents support clinical documentation, clinical decision support and care coordination. Plus, physical agents in robotics systems trained in digital twins of hospitals can scale surgical assistance and hospital automation to meet care demands.
In software, cybersecurity, industrial operations and customer workflows, agents can connect to the tools and data teams already use, helping people move faster through complex workflows.
It all points to the same larger shift: Agents become more useful when they can combine models, tools, skills, runtime and infrastructure in ways companies can adapt to their own workflows. NVIDIA Agent Toolkit provides an open, modular foundation that enables this combination.
Enterprises are moving agentic AI from proof of concept to production — and the next generation of AI factories are built for the era of agents.
At HPE Discover Las Vegas, running through Thursday, June 18, NVIDIA and HPE are expanding the HPE AI Factory with NVIDIA, including NVIDIA Vera CPU and NVIDIA Agent Toolkit for HPE Private Cloud AI.
Plus, NVIDIA Confidential Computing extends across HPE AI Factory and enhanced full-stack NVIDIA integration — with NVIDIA accelerated computing, NVIDIA AI software and NVIDIA networking — is available throughout the entire portfolio.
NVIDIA Vera CPU Available With HPE Private Cloud AI
The HPE ProLiant Compute DL394 Gen12 with the NVIDIA Vera CPU will be available in 2027 with HPE Private Cloud AI, a turnkey AI factory co-engineered with NVIDIA. Vera is the first CPU built for agents — designed for the tool calls, orchestration and real-time data processing required across the agent loop — bringing deterministic, low-latency performance into HPE Private Cloud AI.
The New York Stock Exchange, in collaboration with Redpanda and HPE, is an early enterprise customer exploring Vera CPU with the HPE ProLiant Compute DL394 Gen12 server.
The Vera CPU is part of the NVIDIA Vera Rubin platform, which is ramping into full production with the NVIDIA Vera Rubin NVL72 rack-scale system available from HPE. Vera Rubin was built for frontier-scale models larger than 1 trillion parameters and will ship with full-stack NVIDIA Confidential Computing across every chip.
HPE is also bringing the HPE Compute XD700 — built on NVIDIA HGX Rubin NVL8 — to the HPE AI Factory, supporting up to 128 Rubin GPUs per rack.
NVIDIA Agent Toolkit Now Available With HPE Private Cloud AI
NVIDIA Agent Toolkit — including NVIDIA Nemotron open models, the NVIDIA OpenShell secure runtime and NVIDIA NemoClaw blueprints — will be available with HPE Private Cloud AI. Together, they give enterprises an agentic AI operating system for monitoring agent behavior, enforcing governance policies, and safely building and running autonomous, long-running multi-agent systems.
HPE Private Cloud AI adds secure local agent registration, letting customers approve AI models, skills and tools against centralized governance and security policies before they run. New HPE Zerto Software capabilities detect rogue agent actions and use continuous data protection to rewind to a clean state.
On the data side, HPE Alletra Storage MP X10000 — which achieved the foundation level of NVIDIA-Certified Storage — automatically applies metadata and governance policies to prepare unstructured data for AI pipelines, improving token throughput.
NVIDIA Confidential Computing Across All HPE AI Factory Solutions
NVIDIA Confidential Computing is now available across the HPE AI Factory through HPE Services — including HPE AI Factory at Scale, HPE Sovereign AI Factory and HPE Private Cloud AI.
AI applications access and use private and sensitive data that needs to be protected and secured. In addition, models trained with proprietary data or techniques need to be safeguarded from exfiltration. Confidential computing is essential for these modern AI workloads, as it protects models and private data during execution for on-premises and sovereign deployments, establishing a chain of trust through cryptographic attestation and encryption at every stage.
In addition, HPE ProLiant Compute DL380a achieved certification as part of the NVIDIA-Certified Systems for NVIDIA Confidential Computing program, which validates robust application performance with confidential computing. These systems provide hardware-based protection for AI workloads and sensitive data assets while maintaining optimal NVIDIA acceleration.
Across the HPE AI Factory solutions, NVIDIA BlueField DPUs and NVIDIA DOCA provide in-silicon zero-trust policy enforcement, runtime threat detection and network encryption — protecting AI workloads, agents and data without performance tradeoffs.
Enhanced Full-Stack NVIDIA Integration Across the Portfolio
For next-generation AI factories, every Vera Rubin NVL72 system will ship with NVIDIA networking built in — NVIDIA Vera BlueField-4 DPUs, NVIDIA ConnectX-9 SuperNICs and NVIDIA Spectrum-X Ethernet — with NVIDIA Spectrum-6 switching delivering 1.6x higher networking performance for AI communication versus off-the-shelf Ethernet.
Spectrum-X Ethernet networking is the standard for HPE AI Factory with NVIDIA — including at-scale, sovereign and turnkey AI factory solutions available now. For large-scale and sovereign workloads, HPE announced at NVIDIA GTC in March that it’s also adding NVIDIA InfiniBand networking options — including NVIDIA Quantum-X800 InfiniBand with the HPE Cray Supercomputing GX5000.
These configurations are based on NVIDIA reference architectures and support use cases from AI development through production-scale deployment, with NVIDIA AI Enterprise software and the HPE Unleash AI ecosystem.
At HPE Discover this week, the Unleash AI partner program is expanding with nearly a dozen new AI software partners — including Aizen, BridgeTEK, deepset, Deliverance, Faclon Labs, Gallop, Rocket, Supervity, Thales, Trustwise and Vortiqx.
A year ago at London Tech Week, NVIDIA founder and CEO Jensen Huang and U.K. Prime Minister Keir Starmer made a declaration: the U.K. would be an AI maker, not an AI taker.
At this year’s event, NVIDIA and its partners are showcasing how that commitment is producing real momentum across the nation’s infrastructure, startups and enterprises.
U.K. technology leaders are innovating across healthcare and life sciences, coding, agentic AI, inference and more — all running on sovereign AI deployments.
AI Minister Kanishka Narayan said: “A year ago, we said the UK would be an AI maker, not an AI taker. Today we’re delivering on that — with sovereign compute powering British startups to push the boundaries of what AI can do, from drug discovery to healthcare to robotics. This is what it looks like when a country backs its own talent with the infrastructure to match.
“NVIDIA’s decision to invest billions here is a reflection of the strength of what’s being built in Britain. We are determined to make sure the next generation of AI breakthroughs happens in this country, and we have everything we need to make it happen.”
Commitment to Compute
Over the past year, the number of AI cloud providers planning to deploy AI infrastructure on U.K. soil has doubled.
Nebius has announced plans to expand customers and cloud capabilities with three new deployments of advanced NVIDIA AI infrastructure, as the NVIDIA AI Cloud ecosystem partner continues to build out its commercial and AI R&D hub in London. Combined, the deployments are expected to reach 65 megawatts when fully ramped up in 2027.
CoreWeave is building in the U.K. Government’s AI Growth Zones, and seven more NVIDIA AI Cloud ecosystem partners have plans in the pipeline. BT and Nscale announced plans to build sovereign AI data centers across three existing BT sites in the U.K., combining NVIDIA AI infrastructure, Nscale’s full stack and BT’s trusted nationwide connectivity backbone.
From Fund to Frontier
Central to that sovereign compute story is Isambard-AI — the U.K.’s most powerful computer. Built on 5,400 NVIDIA GH200 Grace Hopper Superchips and running entirely on zero-carbon electricity, it’s the engine behind some of the U.K.’s most ambitious AI research.
The U.K. government’s Sovereign AI Fund is putting that capability to work by backing homegrown companies and providing the domestic infrastructure needed to scale their ambitions.
Among its first recipients is Ineffable Intelligence, which recently announced a collaboration with NVIDIA to build the future of reinforcement learning infrastructure.
Other recipients include four U.K.-based NVIDIA Inception startups, each pushing the AI frontier using Isambard-AI. These startups are:
Cosine Builds Sovereign Coding Platform
Cosine is building an end-to-end sovereign AI coding platform for highly regulated industries such as financial services, critical infrastructure and national security. Using Isambard, Cosine is training a new, large-parameter, mixture-of-experts, multimodal agentic LLM for natively handling data types beyond text and image.
“Access to Isambard enables the project, full stop,” said Alistair Pullen, cofounder and CEO of Cosine. “We already have the people who know how to do this. We have the data. We have the infrastructure and the training. The thing we’ve never had is this level of compute.”
Cursive Trains Self-Improving AI Systems
Cursive is building self-improving AI systems that learn continuously from real-world data, enabling them to operate autonomously over long periods of time. This is unlocked through new memory-augmented architectures with dramatically larger context windows, currently in development using the Sovereign AI Fund resources. In addition, the team recently adopted the NVIDIA Megatron-LM framework for distributed training at scale.
“The Sovereign AI Fund is more than just processing power — it’s a statement about investing in AI in the U.K.,” said Talfan Evans, cofounder and CEO of Cursive. “Sovereignty is actually now a buying criterion — and it’s a challenge to tap into the resources we uniquely have as U.K. and European companies.”
Doubleword Optimizes Inference to Deliver Abundant Intelligence Tokens
Doubleword, the U.K.’s first dedicated inference lab, optimizes every layer of the AI stack to maximize what it calls “IQ per dollar.” The company deploys open models including NVIDIA Nemotron 3 Super 120B and builds on the NVIDIA Dynamo inference framework.
On Isambard, Doubleword’s early results achieved 70x faster model cold starts — aka model loading times — and 4x lossless KV cache compression, critical advancements for long-running agentic workloads. The result: inference at 90-95% lower costs than other leading inference providers.
Image courtesy of Doubleword.
“Sovereign AI is most impactful at the inference layer,” said Meryem Arik, cofounder and CEO of Doubleword. “Inference is when you’re actually getting the value from the model — we want that value created in the U.K., with U.K. compute and U.K. data centers.”
Prima Mente Uses Foundation Models to Study Alzheimer’s and More
Prima Mente builds biological foundation models to identify new biomarkers, subtypes and drug targets of Alzheimer’s, Parkinson’s and ALS. With its Isambard allocation, the company is developing Pleiades 2, a foundation model combining five biological data modalities.
“Research shows Alzheimer’s might be 25 different subgroups of disease, and we want to help by using AI to identify these subtypes and the biology within the cells as they change,” said Hannah Madan, cofounder of Prima Mente.
Video courtesy of Nebius and Prima Mente.
AI Talent, Policy and Production
NVIDIA’s £2 billion investment in the U.K. startup ecosystem — in collaboration with leading venture capital firms — is bringing new capital and advanced AI infrastructure to major U.K. hubs including London, Oxford, Cambridge and Manchester.
U.K. membership in the NVIDIA Inception program has increased by 50% over the past year. AI-native companies like Doubleword, Synthesia and PolyAI are scaling globally from U.K. roots.
At last year’s London Tech Week, NVIDIA announced a collaboration with the U.K Department for Science, Innovation and Technology on 6G and AI skills. The 6G collaboration has seeded testbeds at four U.K. universities. In May, the NVIDIA Deep Learning Institute(DLI) delivered two new courses — added to support the nation’s wireless research community — to participants from over 30 U.K. universities.
The Sovereign AI Forum, which launched last year with seven charter members, convened the country’s AI leadership to turn policy into deployment roadmaps. Over the past year, the Forum has welcomed dozens of participants across government, industry and the startup community — turning policy into deployment roadmaps.
And enterprise AI is moving from pilot to production:
Apian is building digital twins of two National Health Service hospitals, combining autonomous devices, ground robots, computer vision and robotic simulation.
Deliverance AIis helping regulated enterprises to run, govern and scale AI agents inside their own environment — through a single control plane. The Agentic Operating System is built for organizations where data sovereignty is non-negotiable.
Glass Futures has installed an AI-driven digital twin of its glass furnace capable of testing and predicting new, optimal ways to make glass. The digital twin taps into NVIDIA accelerated computing and the NVIDIA PhysicsNeMo framework.
Reading Football Club is partnering with Stelia to establish an AI Centre of Excellence, combining Stelia’s full-stack AI platform with accelerated compute infrastructure from NVIDIA and Lenovo.
It all reflects momentous progress in U.K. AI leadership — and offers a glimpse of where it’s heading.
At this year’s Google I/O conference, NVIDIA and Google Cloud are accelerating the work of more than 100,000 developers in the companies’ joint developer community, which provides curated learning paths, hands-on labs and events that help them build using the full-stack NVIDIA AI platform on Google Cloud.
Launched at Google I/O last year, the community brings together developers, data scientists and machine learning engineers who want to sharpen their AI skills on the latest NVIDIA and Google Cloud technologies.
New additions for the community are rolling out this year, including a learning path for using the JAX library on NVIDIA GPUs, a new NVIDIA Dynamo codelab focused on inference optimizations, as well as monthly developer livestreams.
Over the last year, the community has become a go‑to hub for AI builders using NVIDIA‑accelerated tools for data science and machine learning. The result has been production‑ready retrieval-augmented generation applications on Google Kubernetes Engine (GKE) and instrumenting observability for agent workloads.
These AI builders are also experimenting with new large language model research and prototyping hybrid on‑premises and cloud inference for real‑world use cases like sports analytics and enterprise data pipelines.
Building With Google DeepMind’s Gemma, NVIDIA Nemotron and Open Frameworks
NVIDIA and Google Cloud are equipping developers with learning resources and hands-on labs that combine NVIDIA libraries, open models and tools with Google Cloud’s AI platform — so they can build optimized, production‑ready AI applications faster.
For example, developers can accelerate data science and analytics with the NVIDIA cuDF library in Google Colab Enterprise or Dataproc, or deploy multi-agent applications by combining Google DeepMind’s Gemma 4 models, NVIDIA Nemotron open models and Google Agent Development Kit with Google Cloud G4 VMs powered by NVIDIA RTX PRO 6000 Blackwell GPUs in Google Cloud Run or with spot instances.
NVIDIA and Google Cloud work closely across open frameworks like JAXso developers can build, scale and productize JAX workloads on NVIDIA AI infrastructure on Google Cloud — from single‑GPU experiments to multi‑rack deployments — while getting strong performance and a consistent experience.
This work extends to Google Cloud AI Hypercomputer, where the MaxText framework uses these JAX optimizations to train large models efficiently on NVIDIA GPUs.
Building on the same foundation, NVIDIA Dynamo on GKE helps developers optimize large-scale inference — including mixture-of-experts models — so they can serve AI applications more efficiently with NVIDIA accelerated infrastructure on Google Cloud.
To help developers get hands-on with these capabilities, a new learning path on running and scaling JAX on NVIDIA GPUs and a new NVIDIA Dynamo on GKE inference codelab will become available next month for members in the Google Cloud and NVIDIA developer community.
Advancing Responsible AI With Google DeepMind’s SynthID and NVIDIA Cosmos
AI agents are increasingly built from a system of AI models — combining proprietary and open source models that reason, plan and act on users’ behalf.
Amid this shift, trust and transparency are foundational, so developers and organizations can understand how these systems work and what they generate.
NVIDIA was the first industry partner to collaborate with Google DeepMind on SynthID, an AI watermarking technology that embeds robust digital watermarks directly into AI‑generated content, which helps preserve the integrity of outputs from NVIDIA Cosmos world foundation models available on build.nvidia.com.
Cosmos models provide rich 3D perception and simulation capabilities for robots, autonomous machines and other physical AI systems, while SynthID brings content transparency to the imagery and video they rely on.
Together, they help preserve the integrity of AI‑generated content so developers can build and deploy agentic applications more responsibly across cloud, edge and real‑world environments.
Building on a Full-Stack NVIDIA and Google Cloud Platform
This year, Google I/O is putting the spotlight on new agentic experiences and tools for developers — and NVIDIA and Google Cloud are focused on ensuring builders have the infrastructure, software and learning resources they need to make the most of them.
For developers in the community building on NVIDIA and Google Cloud, the skills and tools they learn can scale, effortlessly taking projects from prototype to enterprise‑grade workloads.
At Google Cloud Next, Google Cloud and NVIDIA expanded their full‑stack platform to help developers train, deploy and operationalize agents on Google Cloud. This collaboration includes work on NVIDIA Vera Rubin-powered A5X instances, Google DeepMind Gemini models and more, and is being harnessed by leading AI labs and enterprises including OpenAI, Thinking Machine Labs, Schrodinger, Salesforce, Snap and Crowdstrike. Learn more in this blog.
Join the NVIDIA and Google Cloud developer community to connect with other builders and stay up to date on new tools, developer events and programs.
Enterprise AI has learned to generate. It has learned to reason. Now companies are asking the next question: How should AI act?
Early agent systems have shown what’s possible, moving beyond simple prompts to take on more complex tasks. The next step is bringing those capabilities into enterprise environments — where agents must operate with context, control and consistency across real workflows.
At ServiceNow Knowledge 2026, NVIDIA founder and CEO Jensen Huang joined ServiceNow chairman and CEO Bill McDermott during the opening keynote to discuss the next phase of enterprise AI.
The companies are expanding their collaboration across the full stack, delivering specialized autonomous AI agents that are safe and easy to adopt — powered by NVIDIA accelerated computing, open models, domain-specific skills and secure agent execution software, and bringing together enterprise workflow context from ServiceNow Action Fabric and governance from ServiceNow AI Control Tower.
ServiceNow is introducing Project Arc, a long-running, self-evolving autonomous desktop agent designed for knowledge workers, including developers, IT teams and administrators.
Unlike standalone AI agents, Project Arc connects natively to the ServiceNow AI Platform through ServiceNow Action Fabric to bring governance, auditability and workflow intelligence to every action the autonomous desktop agent takes. It can access the local file systems, terminals and applications installed on a machine to complete complex, multistep tasks that traditional automation can’t handle, but with the controls enterprises actually need to deploy AI at scale.
The work is designed based on three requirements every company will need for long-running, autonomous agents: open models and domain-specific skills that can be customized and security that helps agents act without exposing sensitive data or systems — all running on AI factories that deliver efficient tokenomics.
Bringing this level of autonomy to enterprises requires control from the start.
Project Arc uses NVIDIA OpenShell, an open source secure runtime for developing and deploying autonomous agents in sandboxed, policy-governed environments. ServiceNow is building on and contributing to OpenShell to advance a common foundation for secure, enterprise-grade agent execution. With OpenShell, enterprises can define what an agent can see, which tools it can use and how each action is contained.
“Project Arc represents the next step in our ongoing collaboration with NVIDIA, bringing autonomous execution to the desktop,” said Jon Sigler, executive vice president and general manager of AI Platform at ServiceNow. “By combining OpenShell’s runtime layer with ServiceNow AI Control Tower, and powered by ServiceNow Action Fabric, we’re delivering the governance and security that enterprise AI requires.”
Open Models and Agent Skills Scale Enterprise AI
To be effective, enterprise AI systems must be adaptable. NVIDIA and ServiceNow are building on an open ecosystem that allows organizations to tailor models and applications to their specific domains and data.
NVIDIA agent skills enable specialized agents, such as ServiceNow AI Specialists, to deliver targeted capabilities across enterprise workflows. For example, the NVIDIA AI-Q Blueprint for building specialized deep research agents empowers ServiceNow AI Specialists to gather context, synthesize information and support more complex decision-making across business functions.
In addition, the NVIDIA Agent Toolkit, including NVIDIA Nemotron open models, provide flexible building blocks and specialized skills for developing customized AI applications. To support real-world performance that these systems can perform reliably, the companies are also advancing NOWAI-Bench, an open benchmarking suite for enterprise AI agents, integrated with the NVIDIA NeMo Gym library. NOWAI-Bench includes EnterpriseOps-Gym, one of the industry’s most challenging enterprise agent benchmarks, where Nemotron 3 Super currently ranks No. 1 among open source models.
Unlike general benchmarks, these evaluations focus on multistep workflows — where enterprise AI systems often encounter real challenges — helping teams build agents that perform reliably in production environments.
Efficient AI Factories
As AI agents become long running and always on, scaling them across millions of workflows requires not just capability but efficiency — making token economics central to enterprise AI.
NVIDIA AI factories are built to deliver the lowest-cost, most-efficient tokenomics for production AI. The NVIDIA Blackwell platform delivers more than 50x greater token output per watt than NVIDIA Hopper, resulting in nearly 35x lower cost per million tokens. For enterprises running agents across millions of workflows, that efficiency can determine how quickly AI moves from pilots to broad production use.
ServiceNow AI Control Tower integrates with the NVIDIA Enterprise AI Factory validated design, extending governance and observability to large-scale AI workloads. With added agent observability capabilities, organizations can monitor behavior in real time and manage AI systems across their full lifecycle — from deployment to optimization.
AI is becoming a new way that work gets done. What’s changing now is that the core pieces required to deploy it at scale — capable agents, built-in guardrails and proven performance — are all coming together.
The companies that move fastest will be the ones that give agents the infrastructure to act, the context to make decisions and the governance to keep every action accountable — and NVIDIA and ServiceNow are making this a reality for the world’s enterprises.
Editor’s note: This post is part of the Nemotron Labs blog series, which explores how the latest open models, datasets and training techniques help businesses build specialized AI systems and applications on NVIDIA platforms. Each post highlights practical ways to use an open stack to deliver real value in production — from transparent research copilots to scalable AI agents.
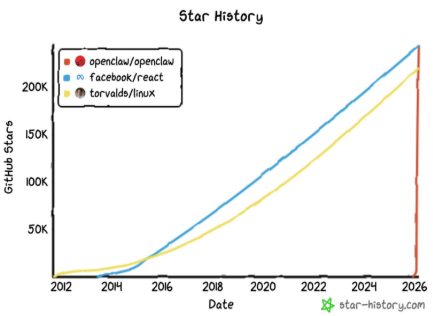
By early 2026, the open source project OpenClaw had become a phenomenon. In January, its GitHub star count crossed 100,000 as developer interest surged. Community dashboards and traffic analytics showed more than 2 million visitors in a single week. By March, OpenClaw topped 250,000 stars — overtaking React to become the most-starred software project on GitHub in just 60 days.
Created by Peter Steinberger, OpenClaw is a self-hosted, persistent AI assistant designed to run locally or on private servers. The project drew attention for its accessibility and unbounded autonomy: Users could deploy an AI model locally without depending on cloud infrastructure or external application programming interfaces (APIs).
Most AI agents today are triggered by a prompt, complete a defined task and then stop running. A long-running autonomous agent, or “claw,” works differently. These agents run persistently in the background, completing tasks on their own and surfacing only what requires a human decision. They operate on a heartbeat: At regular intervals, they check their task list, evaluate what needs action, and either act or wait for the next cycle.
OpenClaw’s rapid adoption also sparked debate. Security researchers raised concerns about how self-hosted AI tools manage sensitive data, authentication and model updates. Others questioned whether local deployments could expose users to new risks — from unpatched server instances to malicious contributions in community forks. As contributors and maintainers worked to address these issues, OpenClaw’s rise prompted a broader conversation across the AI ecosystem about the trade-offs between openness, privacy and safety.
To help enhance the security and robustness of the OpenClaw project, NVIDIA is collaborating with Steinberger and the OpenClaw developer community to address potential vulnerabilities, as detailed in a recent blog post by OpenClaw.
NVIDIA contributes code and guidance focused on improving model isolation, better managing local data access and strengthening the processes for verifying community code contributions. The goal is to support the project’s momentum by contributing its security and systems expertise in an open, transparent way that strengthens the community’s work while preserving OpenClaw’s independent governance.
To help make long-running agents safer for enterprises, NVIDIA also introduced NVIDIA NemoClaw, a reference implementation that uses a single command to install OpenClaw, the NVIDIA OpenShell secure runtime and NVIDIA Nemotron open models with hardened defaults for networking, data access and security. NemoClaw serves as a blueprint for organizations to deploy claws more securely.
Inference Demand Multiplies With Each AI Wave
AI has moved through four phases, and the time between each is shortening. Predictive AI took years to become mainstream. Generative AI moved faster. Reasoning AI arrived faster still. Autonomous AI — the wave OpenClaw represents — is setting an even faster pace.
What compounds with each wave is inference demand. Generative AI increased token usage over predictive AI. Reasoning AI increased it another 100x. Autonomous agents, which run continuously and act across long time horizons, drive inference demand up by another 1,000x over reasoning AI. Each wave multiplies the compute required.
This increase in token usage is enabling organizations to speed their productivity by orders of magnitude. For example, long-running agents can help researchers work through a problem overnight, iterate on a design across thousands of configurations, or monitor systems and surface only the anomalies that require human judgment — freeing up researchers’ work days for higher-value tasks.
Choosing the Tool: When to Deploy a ‘Claw’
While generative AI has become a staple for on-demand tasks, there are specific scenarios where the persistent “heartbeat” of a claw offers distinct advantages. Determining when to move from a standard prompt-based AI to a long-running agent often comes down to the nature of the workflow:
From “On-Demand” to “Always-On”: While standard models are excellent for immediate, human-triggered queries, claws are often better suited for tasks that require continuous background monitoring or periodic system checks without a manual start.
Managing High-Iteration Loops: For complex problems, like testing thousands of chemical combinations or simulating infrastructure stress tests, a claw can manage the sheer volume of iterations that might otherwise be bottlenecked by human intervention.
Shifting from Suggestions to Actions: In many workflows, standard AI is used to provide information or drafts. A claw is often considered when the goal is for the AI to move into the execution phase — interacting with APIs, updating databases or managing files across a long time horizon.
Resource Optimization: For massive, token-heavy reasoning tasks, deploying a local claw on dedicated hardware like an NVIDIA DGX Spark personal AI supercomputer allows for more predictable costs and data privacy compared with high-frequency cloud API calls.
How Are Organizations Using Long-Running Autonomous Agents?
The practical applications of long-running autonomous agents span every function and sector.
In financial services, agents continuously monitor trading systems and regulatory feeds, flagging material events before the morning review. In drug discovery, agents sweep new scientific literature, extracting relevant findings and updating internal databases in real time without researcher intervention — a process that previously took weeks.
In engineering and manufacturing, agents speed problem analysis by testing thousands of parameter combinations, ranking results and flagging the configurations worth examining — and all this can happen overnight.
In IT operations, agents diagnose infrastructure incidents, apply known remediations and escalate only the novel problems — compressing average time to resolution from hours to minutes. At ServiceNow, AI specialists leveraging Apriel and NVIDIA Nemotron models can resolve 90% of tickets autonomously.
How Can Companies Deploy Autonomous Agents Responsibly?
Autonomous agents are hands-on. They can send communications, write files, call APIs and update live systems. When an agent produces a wrong action, there are real consequences. Getting the accountability framework right from the start is essential, and organizations deploying autonomous agents in production must treat governance as a first-order requirement.
Organizations need to see what their agents are doing, inspect their reasoning at each step, audit their actions and intervene when needed.
Organizations deploying autonomous agents responsibly are focused on three priorities:
An open, auditable framework: NemoClaw is built on OpenClaw’s MIT licensed codebase, which means organizations own the full agent harness. They can read, fork and modify every layer of how their agents are built and deployed. That transparency enables teams to understand and control the system at the code level. Running open source models like NVIDIA Nemotron locally keeps sensitive workloads, including patient records, legal documents, financial transactions and proprietary research, within the organization’s own environment, ensuring that trace data stays under organizational control.
Securing the runtime environment:NemoClaw runs agents inside OpenShell, a sandboxed environment that defines precisely what the agent can and cannot do, enforcing clear permission boundaries from the start.
Local compute: NVIDIA DGX Spark supercomputers deliver data-center-class GPU performance in a deskside form factor built for continuous local inference that’s always on, with local model hosting and data that stays within the organization’s environment. NVIDIA DGX Station systems scale that capability for teams running multiple agents simultaneously across complex, sustained workloads.
The organizations defining what autonomous agents do in practice are accumulating something valuable: months of live operational learning, governance frameworks developed through real workloads and agents that have absorbed the institutional context that makes them genuinely useful. This foundation will only deepen over time.
AI agent systems today juggle separate models for vision, speech and language — losing time and context as they pass data from one model to the other.
Unveiled today, NVIDIA Nemotron 3 Nano Omni is an open multimodal model that brings these capabilities together into one system, enabling agents to deliver faster, smarter responses with advanced reasoning across video, audio, image and text. This best-in-class model gives enterprises and developers a production path for more efficient and accurate multimodal AI agents with full deployment flexibility and control.
Nemotron 3 Nano Omni sets a new efficiency frontier for open multimodal models with leading accuracy and low cost, topping six leaderboards for complex document intelligence, and video and audio understanding.
“To build useful agents, you can’t wait seconds for a model to interpret a screen,”said Gautier Cloix, CEO of H Company.“By building on Nemotron 3 Nano Omni, our agents can rapidly interpret full HD screen recordings — something that wasn’t practical before. This isn’t just a speed boost: It’s a fundamental shift in how our agents perceive and interact with digital environments in real time.”
Nemotron 3 Nano Omni Enables Faster, Leaner Multimodal Agents
Consider an AI agent for customer support processing a screen recording while analyzing uploaded call audio and checking data logs — or an agent for finance tasked with parsing PDFs, spreadsheets, charts and voice notes. Today, most agentic systems accomplish these tasks with separate models for vision, speech and language.
This approach increases latency through repeated inference passes, fragments context across modalities, and adds cost and inaccuracies over time.
By combining vision and audio encoders within its 30B-A3B, hybrid mixture-of-experts architecture, Nemotron 3 Nano Omni eliminates the need for separate perception models, driving inference efficiency at scale. It pairs this efficiency with strong multimodal perception accuracy, enabling AI systems to achieve 9x higher throughput than other open omni models with the same interactivity. The result is lower costs and better scalability without sacrificing responsiveness or quality.
In agentic systems, Nemotron 3 Nano Omni can work alongside proprietary cloud models or other NVIDIA Nemotron open models — such as Nemotron 3 Super for high-frequency execution or Nemotron 3 Ultra for complex planning — as well as proprietary models from other providers, to power sub-agents for agentic workflows such as computer use, document intelligence and audio-video reasoning.
Computer use agents — Nemotron 3 Nano Omni powers the perception loop for agents navigating graphical user interfaces, reasoning over onscreen content and understanding user interface state over time. H Company’s latest computer usage agent, powered by Nemotron 3 Nano Omni, uses a native input resolution of 1920×1080 pixels to achieve high-fidelity visual reasoning. In preliminary evaluations on the OSWorld benchmark, this integration showed a significant leap in navigating complex graphical interfaces and used Nemotron 3 Nano Omni’s ability to process very high-resolution images.
Document intelligence — Interprets documents, charts, tables, screenshots and mixed-media inputs, enabling agents to reason across visual structure and text content coherently. Critical for enterprise analysis and compliance workflows.
Audio and video understanding — For customer service, research and monitoring workflows, Nemotron 3 Nano Omni maintains audio-video context, tying what was said, shown and documented into a single reasoning stream instead of disconnected summaries.
Open and Customizable, Deployable Anywhere
Nemotron 3 Nano Omni is released with open weights, datasets and training techniques — giving organizations full transparency and control over how the model is customized and deployed.
Developers can use tools like NVIDIA NeMo for customization, evaluation and optimization for domain-specific use cases. Because the Nemotron family of models is open, organizations can deploy them in environments that meet regulatory, sovereignty or data localization requirements. The Nemotron 3 family — including Nano, Super and Ultra models — has seen over 50 million downloads in the past year. Omni extends the family’s capabilities into multimodal and agentic domains.
Its open, lightweight architecture supports consistent deployment from local systems like NVIDIA Jetson modules, NVIDIA DGX Spark and DGX Station to data center and cloud environments.
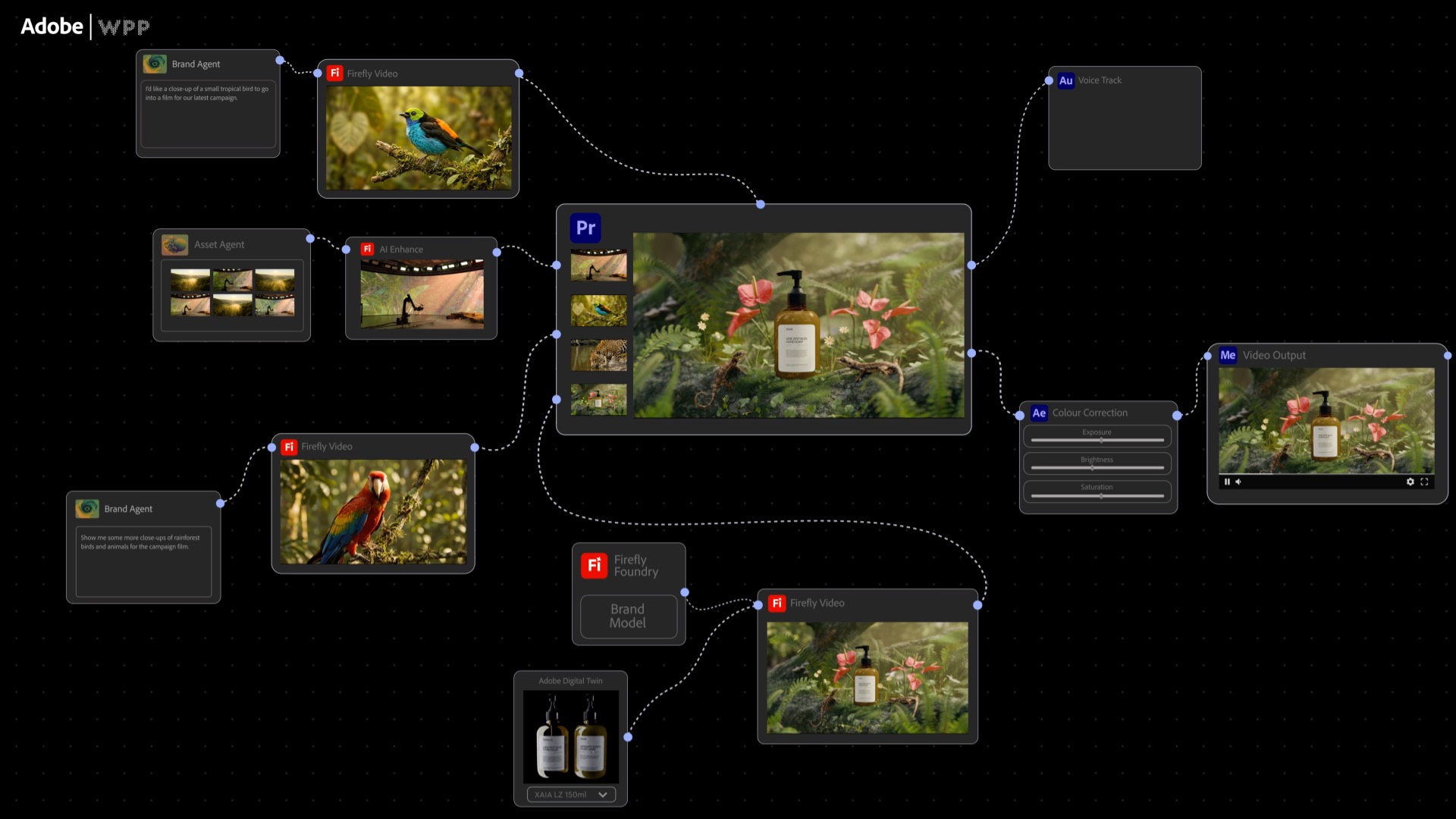
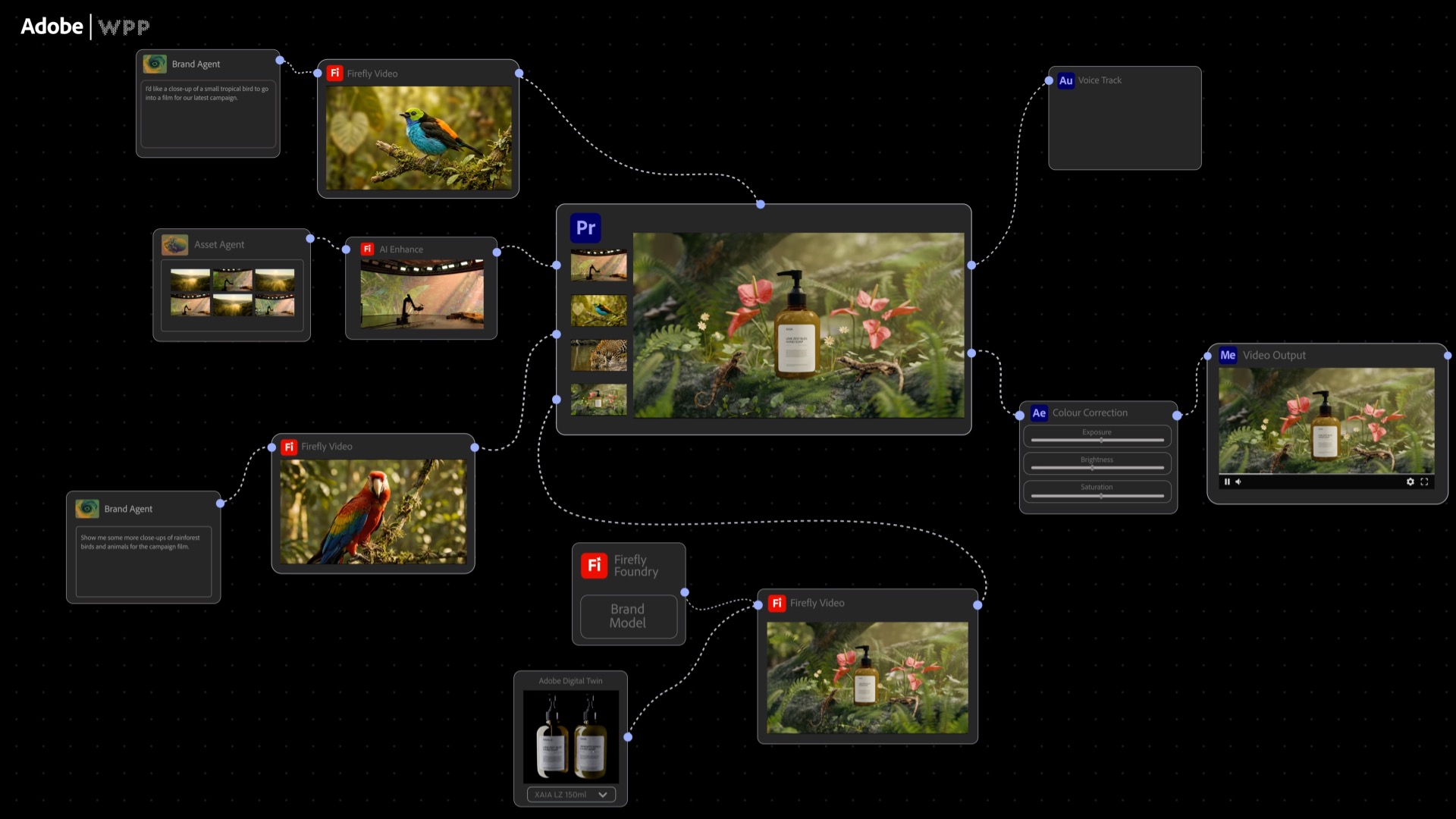
As demand for personalized customer experiences surges, brands require intelligent systems that can plan, create, produce and activate content continuously — without compromising control, governance or brand integrity.
Consider a global retailer delivering the right offer, image, copy and price, across millions of product, audience and channel combinations — updated in minutes instead of months.
For marketing and creative teams, that means moving from one-size-fits-all campaigns to tailored experiences that are always on, always relevant and on brand. All of it is powered by intelligent systems that continuously generate and deliver content without sacrificing control, governance or brand integrity.
The expanded collaborations bring together three complementary strengths: Adobe’s creative and customer experience platforms and the new Adobe CX Enterprise Coworker, WPP’s global media and marketing expertise, and NVIDIA’s accelerated computing and software stack, including NVIDIA Nemotron open models, NVIDIA Agent Toolkit and the NVIDIA OpenShell secure runtime for building and running secure agentic AI systems.
As these agents begin orchestrating multistep workflows, tapping sensitive data and triggering actions across marketing stacks, enterprises need a way to enforce clear rules of engagement so every operation remains compliant, on brand and within defined risk boundaries.
Powered by the NVIDIA OpenShell runtime, every agent operates within a secure, isolated environment, delivering enterprise-grade control, consistency and auditability across the entire marketing lifecycle, with verifiable policy management, answering the question, “What can the agent do?” and not just, “What policy is in place?”
In governed environments, enterprises can also keep key workflows and intelligence services inside their trust boundary, including securely invoking Adobe CX Intelligence as part of customer experience agents.
A live demo of CX Enterprise Coworker — powered by NVIDIA Agent Toolkit, including the OpenShell runtime and Nemotron models — will be featured during Adobe Summit’s day-two keynote taking place Tuesday, April 21, at 9 a.m. PT.
The collaboration enables:
End-to-end agentic workflows: Adobe is developing creative and marketing agents that can generate, adapt and version on-brand assets. Adobe’s CX Enterprise Coworker orchestrates downstream customer experience workflows from personalization to activation, closing the loop between content creation and customer engagement.
Controlled execution with NVIDIA OpenShell: Agents run in a policy-based, containerized sandbox designed to keep execution governed, observable and auditable, helping enterprises safely deploy long-running agentic workflows on premises or in the cloud.
Commercially safe content at scale: Adobe Firefly Foundry, accelerated by NVIDIA AI infrastructure, can help organizations deeply tune custom models on their proprietary assets, enabling agents to generate commercially safe content at scale and aligned to brand identity.
A 3D digital twins solution for scalable marketing production: Adobe’s cloud-native 3D digital twin solution is now generally available, built on NVIDIA Omniverse libraries and OpenUSD. 3D digital twins serve as persistent product identities that agents use to automate and scale high-fidelity content creation across formats, markets and configurations.
Creative Intelligence Meets Performance Intelligence With Policy-Governed Agents
Governed environments such as the ones enabled by this collaboration act as a set of “guardrails” that keep AI operations observable and auditable, preventing the system from acting outside of a company’s specific data boundaries or brand rules.
By combining Adobe’s creative platforms, WPP’s media and marketing expertise and NVIDIA’s secure infrastructure with CX Enterprise Coworker, brands no longer have to choose between speed and safety. Autonomous agents can now generate, adapt and activate content at scale while operating within governed, policy-driven environments.
The result is a new foundation for agentic marketing — where creative intelligence, performance and trust are built in from the start and delivered at global scale.
Watch NVIDIA founder and CEO Jensen Huang’s Adobe Summit fireside chat with Adobe CEO Shantanu Narayen below.
Launched today, NVIDIA Nemotron 3 Super is a 120‑billion‑parameter open model with 12 billion active parameters designed to run complex agentic AI systems at scale.
Available now, the model combines advanced reasoning capabilities to efficiently complete tasks with high accuracy for autonomous agents.
AI-Native Companies: Perplexity offers its users access to Nemotron 3 Super for search and as one of 20 orchestrated models in Computer. Companies offering software development agents like CodeRabbit, Factory and Greptile are integrating the model into their AI agents along with proprietary models to achieve higher accuracy at lower cost. And life sciences and frontier AI organizations like Edison Scientific and Lila Sciences will power their agents for deep literature search, data science and molecular understanding.
Enterprise Software Platforms: Industry leaders such as Amdocs, Palantir, Cadence, Dassault Systèmes and Siemens are deploying and customizing the model to automate workflows in telecom, cybersecurity, semiconductor design and manufacturing.
As companies move beyond chatbots and into multi‑agent applications, they encounter two constraints.
The first is context explosion. Multi‑agent workflows generate up to 15x more tokens than standard chat because each interaction requires resending full histories, including tool outputs and intermediate reasoning.
Over long tasks, this volume of context increases costs and can lead to goal drift, where agents lose alignment with the original objective.
The second is the thinking tax. Complex agents must reason at every step, but using large models for every subtask makes multi-agent applications too expensive and sluggish for practical applications.
Nemotron 3 Super has a 1‑million‑token context window, allowing agents to retain full workflow state in memory and preventing goal drift. Nemotron 3 Super has set new standards, claiming the top spot on Artificial Analysis for efficiency and openness with leading accuracy among models of the same size.
The model also powers the NVIDIA AI-Q research agent to the No. 1 position on DeepResearch Bench and DeepResearch Bench II leaderboards, benchmarks that measure an AI system’s ability to conduct thorough, multistep research across large document sets while maintaining reasoning coherence.
Hybrid Architecture
Nemotron 3 Super uses a hybrid mixture‑of‑experts (MoE) architecture that combines three major innovations to deliver up to 5x higher throughput and up to 2x higher accuracy than the previous Nemotron Super model.
Hybrid Architecture: Mamba layers deliver 4x higher memory and compute efficiency, while transformer layers drive advanced reasoning.
MoE: Only 12 billion of its 120 billion parameters are active at inference.
Latent MoE: A new technique that improves accuracy by activating four expert specialists for the cost of one to generate the next token at inference.
Multi-Token Prediction: Predicts multiple future words simultaneously, resulting in 3x faster inference.
On the NVIDIA Blackwell platform, the model runs in NVFP4 precision. That cuts memory requirements and pushes inference up to 4x faster than FP8 on NVIDIA Hopper, with no loss in accuracy.
Open Weights, Data and Recipes
NVIDIA is releasing Nemotron 3 Super with open weights under a permissive license. Developers can deploy and customize it on workstations, in data centers or in the cloud.
The model was trained on synthetic data generated using frontier reasoning models. NVIDIA is publishing the complete methodology, including over 10 trillion tokens of pre- and post-training datasets, 15 training environments for reinforcement learning and evaluation recipes. Researchers can further use the NVIDIA NeMo platform to fine-tune the model or build their own.
Use in Agentic Systems
Nemotron 3 Super is designed to handle complex subtasks inside a multi-agent system.
A software development agent can load an entire codebase into context at once, enabling end-to-end code generation and debugging without document segmentation.
In financial analysis it can load thousands of pages of reports into memory, eliminating the need to re-reason across long conversations, which improves efficiency.
Nemotron 3 Super has high-accuracy tool calling that ensures autonomous agents reliably navigate massive function libraries to prevent execution errors in high-stakes environments, like autonomous security orchestration in cybersecurity.
Availability
NVIDIA Nemotron 3 Super, part of the Nemotron 3 family, can be accessed at build.nvidia.com, Perplexity, OpenRouterand Hugging Face. Dell Technologies is bringing the model to the Dell Enterprise Hub on Hugging Face, optimized for on-premise deployment on the Dell AI Factory, advancing multi-agent AI workflows. HPE is also bringing NVIDIA Nemotron to its agents hub to help ensure scalable enterprise adoption of agentic AI.
Enterprises and developers can deploy the model through several partners:
Cloud Service Providers: Google Cloud’s Vertex AI and Oracle Cloud Infrastructure, and coming soon to Amazon Web Services through Amazon Bedrock as well as Microsoft Azure.
Autonomous networks — intelligent, self-managing telecommunications operations — are moving from a future vision to a current priority for telecom operators. In the latest NVIDIA State of AI in Telecommunications report, network automation emerged as the top AI use case for investment and return on investment.
Automation is different from autonomy. Beyond executing predefined workflows, autonomous networks must understand operator intent, reason over tradeoffs and decide what actions to take. Reasoning models and AI agents fine-tuned on telecom data are key to enabling this shift.
For networks to become autonomous, there’s a need for an end-to-end agentic system that includes key components like telco network models and AI agents that talk to each other and use network simulation tools to validate actions.
Ahead of Mobile World Congress Barcelona, NVIDIA unveiled an open NVIDIA Nemotron-based large telco model (LTM), a comprehensive guide for building reasoning agents for network operations, and new NVIDIA Blueprints for energy saving and network configuration with multi-agent orchestration to help operators advance toward autonomy.
And as part of GSMA’s new Open Telco AI initiative — launching tomorrow — NVIDIA is releasing the new open source LTM, implementation guide and agentic AI blueprints as open resources through GSMA, an organization for the mobile communications industry.
Open Nemotron 3 Large Telco Model Brings Reasoning to Telecom
For telcos to successfully operationalize generative and agentic AI across their operations, AI models must have the ability to understand the language of telecom and reason through complex workflows. NVIDIA has collaborated with AdaptKey AI to release a new open source, 30-billion-parameter NVIDIA Nemotron LTM that operators around the world can use to build autonomous networks.
Built on the NVIDIA Nemotron 3 family of foundation models and fine-tuned by AdaptKey AI using open telecom datasets including industry standards and synthetic logs, the LTM is optimized to understand telecom industry terminology and reason through workflows such as fault isolation, remediation planning and change validation.
As an open model, the Nemotron LTM gives telcos full transparency into how it was trained and what data was used, enabling secure and fast on‑premises deployment within their networks, where they can build and run agents directly. It also lets telcos safely adapt and extend telecom‑tuned reasoning with their own network and operational data, so they can move toward autonomous operations without sacrificing control over data or security.
Teaching AI Agents to Reason Like Network Engineers
NVIDIA and Tech Mahindra have published an open source guide that shows telecom operators how to fine-tune domain-specific reasoning models and build agents that can safely execute network operations center (NOC) workflows.
The guide outlines a framework for teaching models to reason like NOC engineers: focus on high‑impact, high‑frequency incident categories, translate expert resolutions into step‑by‑step procedures and turn those into structured reasoning traces that capture each action, tool call, outcome and decision. These traces become the “thinking examples” the model learns from, so it understands not just what to do, but why a particular sequence of checks and fixes is safe and effective.
Using the NVIDIA NeMo-Skills pipeline, operators can fine-tune a reasoning model on these traces, laying the foundation for telco-specialized AI agents that can reason and solve problems like a network engineer.
Maximizing Energy Efficiency With New Intent-Driven Energy Saving Blueprint
Autonomous networks rely on closed‑loop operation: models that understand the network, agents that act on intent and simulation that feeds results back into the system to validate and refine decisions. The new NVIDIA Blueprint for intent-driven RAN energy efficiency brings these pieces together, helping operators systematically reduce power consumption in 5G radio access networks (RAN) while maintaining quality of service.
The blueprint integrates network test and measurement leader VIAVI’s TeraVM AI RAN Scenario Generator (AI RSG) platform to generate synthetic network data — including cell utilization, user throughput and other traffic patterns — and convert it into a simple, queryable format.
An energy planning agent then reasons over the synthetic data to generate energy-saving policies that can be simulated in AI RSG, allowing operators to safely validate energy-saving policies in a closed loop to meet their intent without changing live configurations or impacting subscribers.
Telcos Put the NVIDIA Blueprint for Network Configuration to Work
Cassava Technologies is using the blueprint to build Cassava Autonomous Network, an agentic platform designed to optimize Africa’s diverse, multi-vendor mobile network environment. The platform implements three agents: one to monitor the network and recommend configuration changes, one to apply changes with documentation and governance, and one to assess the impact of changes made and safely roll them back if they have unintended effects.
NTT DATA is implementing the blueprint to bring intelligence to traffic regulation, helping the network manage surges when users reconnect after an outage, and is deploying it with a tier 1 operator in Japan.
An AI agent looks at real-time demand across the network and then decides when and how to admit new users on specific cells. As conditions stabilize, the agent adapts its decisions, turning what used to be manual configurations into a data-driven optimization cycle for more resilient mobile networks.
Evolving Network Configuration With Multi-Agent Orchestration
BubbleRAN is integrating NAT and BAT into its Opti-Sphere platform to manage network monitoring, configuration and validation agents more flexibly across containers and workloads, and connect them to tools that report network metrics and traffic status so they can continuously propose and validate configuration changes.
Telenor Group will be the first telco to adopt the blueprint with BubbleRAN to enhance its 5G network for Telenor Maritime, the group’s global connectivity provider at sea.
Learn more about the latest advancements in agentic AI for telecommunications at Mobile World Congress, taking place in Barcelona from March 2-5.
See notice regarding software product information.