
Editor’s note: This post is part of the Nemotron Labs blog series, which explores how the latest open models, datasets and training techniques help businesses build specialized AI systems and applications on NVIDIA platforms. Each post highlights practical ways to use an open stack to deliver real value in production — from transparent research copilots to scalable AI agents.
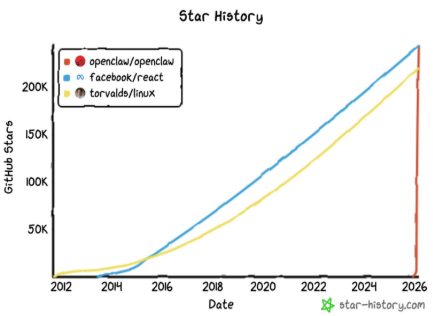
By early 2026, the open source project OpenClaw had become a phenomenon. In January, its GitHub star count crossed 100,000 as developer interest surged. Community dashboards and traffic analytics showed more than 2 million visitors in a single week. By March, OpenClaw topped 250,000 stars — overtaking React to become the most-starred software project on GitHub in just 60 days.
Created by Peter Steinberger, OpenClaw is a self-hosted, persistent AI assistant designed to run locally or on private servers. The project drew attention for its accessibility and unbounded autonomy: Users could deploy an AI model locally without depending on cloud infrastructure or external application programming interfaces (APIs).
Most AI agents today are triggered by a prompt, complete a defined task and then stop running. A long-running autonomous agent, or “claw,” works differently. These agents run persistently in the background, completing tasks on their own and surfacing only what requires a human decision. They operate on a heartbeat: At regular intervals, they check their task list, evaluate what needs action, and either act or wait for the next cycle.
OpenClaw’s rapid adoption also sparked debate. Security researchers raised concerns about how self-hosted AI tools manage sensitive data, authentication and model updates. Others questioned whether local deployments could expose users to new risks — from unpatched server instances to malicious contributions in community forks. As contributors and maintainers worked to address these issues, OpenClaw’s rise prompted a broader conversation across the AI ecosystem about the trade-offs between openness, privacy and safety.
To help enhance the security and robustness of the OpenClaw project, NVIDIA is collaborating with Steinberger and the OpenClaw developer community to address potential vulnerabilities, as detailed in a recent blog post by OpenClaw.
NVIDIA contributes code and guidance focused on improving model isolation, better managing local data access and strengthening the processes for verifying community code contributions. The goal is to support the project’s momentum by contributing its security and systems expertise in an open, transparent way that strengthens the community’s work while preserving OpenClaw’s independent governance.
To help make long-running agents safer for enterprises, NVIDIA also introduced NVIDIA NemoClaw, a reference implementation that uses a single command to install OpenClaw, the NVIDIA OpenShell secure runtime and NVIDIA Nemotron open models with hardened defaults for networking, data access and security. NemoClaw serves as a blueprint for organizations to deploy claws more securely.
Inference Demand Multiplies With Each AI Wave
AI has moved through four phases, and the time between each is shortening. Predictive AI took years to become mainstream. Generative AI moved faster. Reasoning AI arrived faster still. Autonomous AI — the wave OpenClaw represents — is setting an even faster pace.
What compounds with each wave is inference demand. Generative AI increased token usage over predictive AI. Reasoning AI increased it another 100x. Autonomous agents, which run continuously and act across long time horizons, drive inference demand up by another 1,000x over reasoning AI. Each wave multiplies the compute required.

This increase in token usage is enabling organizations to speed their productivity by orders of magnitude. For example, long-running agents can help researchers work through a problem overnight, iterate on a design across thousands of configurations, or monitor systems and surface only the anomalies that require human judgment — freeing up researchers’ work days for higher-value tasks.
Choosing the Tool: When to Deploy a ‘Claw’
While generative AI has become a staple for on-demand tasks, there are specific scenarios where the persistent “heartbeat” of a claw offers distinct advantages. Determining when to move from a standard prompt-based AI to a long-running agent often comes down to the nature of the workflow:
- From “On-Demand” to “Always-On”: While standard models are excellent for immediate, human-triggered queries, claws are often better suited for tasks that require continuous background monitoring or periodic system checks without a manual start.
- Managing High-Iteration Loops: For complex problems, like testing thousands of chemical combinations or simulating infrastructure stress tests, a claw can manage the sheer volume of iterations that might otherwise be bottlenecked by human intervention.
- Shifting from Suggestions to Actions: In many workflows, standard AI is used to provide information or drafts. A claw is often considered when the goal is for the AI to move into the execution phase — interacting with APIs, updating databases or managing files across a long time horizon.
- Resource Optimization: For massive, token-heavy reasoning tasks, deploying a local claw on dedicated hardware like an NVIDIA DGX Spark personal AI supercomputer allows for more predictable costs and data privacy compared with high-frequency cloud API calls.
How Are Organizations Using Long-Running Autonomous Agents?
The practical applications of long-running autonomous agents span every function and sector.
In financial services, agents continuously monitor trading systems and regulatory feeds, flagging material events before the morning review. In drug discovery, agents sweep new scientific literature, extracting relevant findings and updating internal databases in real time without researcher intervention — a process that previously took weeks.
In engineering and manufacturing, agents speed problem analysis by testing thousands of parameter combinations, ranking results and flagging the configurations worth examining — and all this can happen overnight.
In IT operations, agents diagnose infrastructure incidents, apply known remediations and escalate only the novel problems — compressing average time to resolution from hours to minutes. At ServiceNow, AI specialists leveraging Apriel and NVIDIA Nemotron models can resolve 90% of tickets autonomously.
How Can Companies Deploy Autonomous Agents Responsibly?
Autonomous agents are hands-on. They can send communications, write files, call APIs and update live systems. When an agent produces a wrong action, there are real consequences. Getting the accountability framework right from the start is essential, and organizations deploying autonomous agents in production must treat governance as a first-order requirement.
Organizations need to see what their agents are doing, inspect their reasoning at each step, audit their actions and intervene when needed.
Organizations deploying autonomous agents responsibly are focused on three priorities:
- An open, auditable framework: NemoClaw is built on OpenClaw’s MIT licensed codebase, which means organizations own the full agent harness. They can read, fork and modify every layer of how their agents are built and deployed. That transparency enables teams to understand and control the system at the code level. Running open source models like NVIDIA Nemotron locally keeps sensitive workloads, including patient records, legal documents, financial transactions and proprietary research, within the organization’s own environment, ensuring that trace data stays under organizational control.
- Securing the runtime environment: NemoClaw runs agents inside OpenShell, a sandboxed environment that defines precisely what the agent can and cannot do, enforcing clear permission boundaries from the start.
- Local compute: NVIDIA DGX Spark supercomputers deliver data-center-class GPU performance in a deskside form factor built for continuous local inference that’s always on, with local model hosting and data that stays within the organization’s environment. NVIDIA DGX Station systems scale that capability for teams running multiple agents simultaneously across complex, sustained workloads.
The organizations defining what autonomous agents do in practice are accumulating something valuable: months of live operational learning, governance frameworks developed through real workloads and agents that have absorbed the institutional context that makes them genuinely useful. This foundation will only deepen over time.
Get Started With NVIDIA NemoClaw
Access a step-by-step tutorial on how to build a more secure AI agent with NemoClaw on NVIDIA DGX Spark. Explore how NemoClaw can deploy more secure, always-on AI assistants with a single command.
Experiment with NemoClaw, available on GitHub, and join the community of developers on Discord building with NemoClaw using NVIDIA Nemotron 3 Super and Telegram on DGX Spark.
Stay up to date on agentic AI, NVIDIA Nemotron and more by subscribing to NVIDIA AI news, joining the community and following NVIDIA AI on LinkedIn, Instagram, X and Facebook.

